Using dcifer to estimate relatedness from biallelic SNP data
Author
Kathryn Murie
Published
December 11, 2023
The data
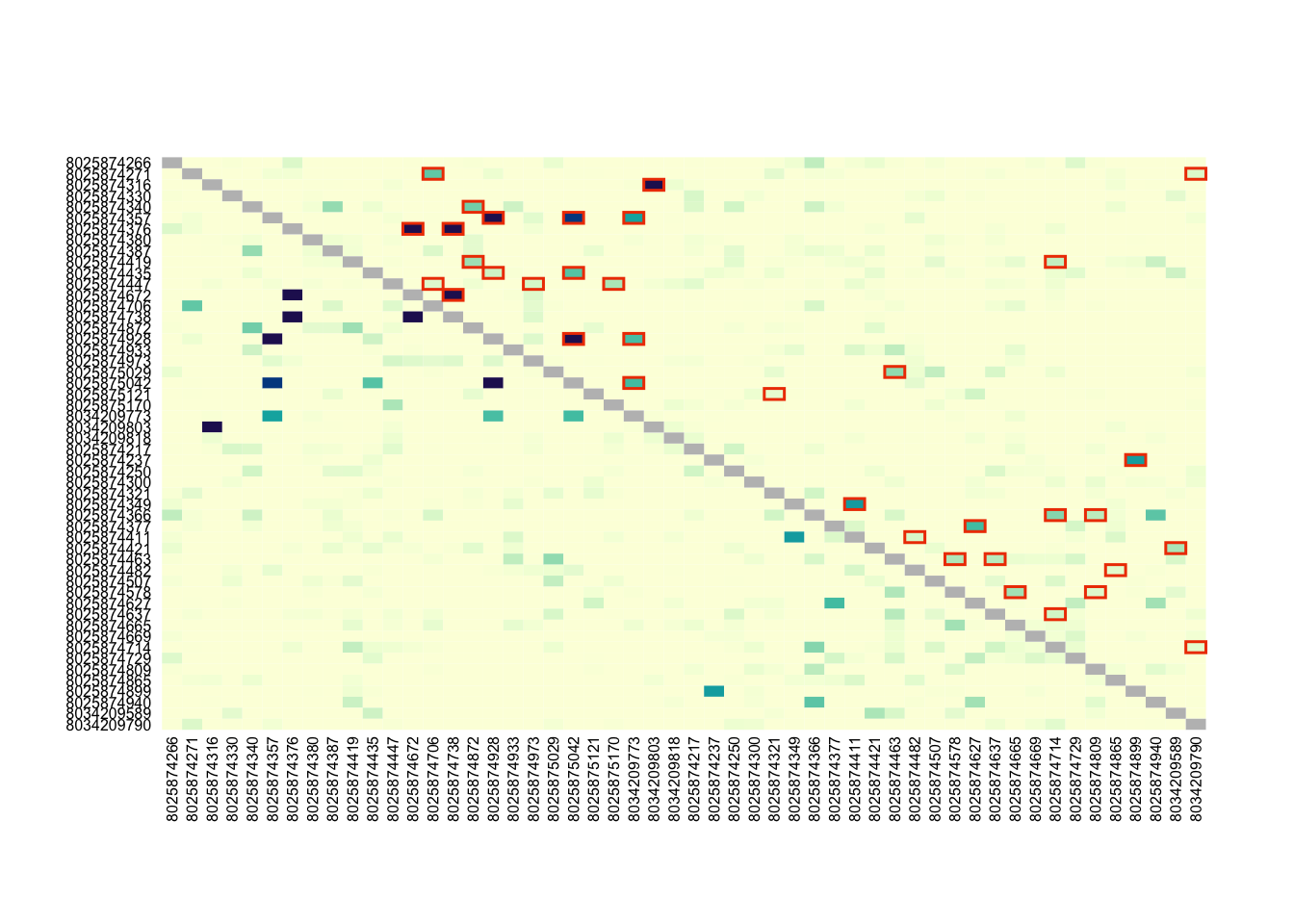
Below we will demonstrate how to use dcifer using biallelic Sanger 100-SNP barcode data in .vcf format. We will use data created by simulating 100 polyclonal infections from Bangladesh (n=50) and Ghana (n=50). See the PGEforge website for further details.
In this tutorial we will use PGEhammer to convert data from the VCF format to the format required by Dcifer. To install the package run the following command
# Install PGEhammer in R:install.packages('PGEhammer', repos =c('https://plasmogenepi.r-universe.dev', 'https://cloud.r-project.org'))
The downloaded binary packages are in
/var/folders/wx/rr171mzs0lj0mtflng6dwl7h0000gp/T//Rtmp8DqrQV/downloaded_packages
Dcifer requires input data in long format, the long format represents data with each observation on a separate row. This data can be biallelic or multiallelic. In the following steps, we will convert the Variant Call Format (VCF) data to the required long format using the function vcf2long from PGEhammer.
Before we calculate IBD we first need to calculate COI. Below we use the function getCOI that Dcifer provides which uses naive estimation, but you could use another tool for this.
lrank <-2coi <-getCOI(dsmp, lrank = lrank)
The last thing we need to do before calculating IBD is to add in allele frequencies. Again we use a function within Dcifer for this, calcAfreq.
afreq <-calcAfreq(dsmp, coi, tol =1e-5) str(afreq, list.len =2)
List of 87
$ t1 : Named num [1:5] 0.4239 0.2808 0.1116 0.0422 0.1415
..- attr(*, "names")= chr [1:5] "D10--D6--FCR3--V1-S.0" "HB3.0" "t1.0" "t1.1" ...
$ t10 : Named num [1:4] 0.8539 0.00942 0.00951 0.12717
..- attr(*, "names")= chr [1:4] "D10--D6--HB3.0" "t10.0" "t10.2" "U659.0"
[list output truncated]
In summary, we have used Dcifer to estimate COI and allele frequencies before estimating IBD. Dcifer has extensive documentation, including more details on other functionality available within the tool and a tutorial using microhaplotype data.