mcstate sits at the top of a stack of packages, which together allow inference of a stochastic model’s parameters by fitting to a time-series of observational data. To use mcstate, we require the following pieces:
- A generative model for a state-space process, implemented in
dust. This will generate (stochastic) updates of the state at each time step. - A time-series of observed data, which may include from multiple sources (e.g. cases, hospital beds, deaths).
- A comparison function, which calculates the likelihood of a model state, given the observed data.
- Optionally an index function, which identifies the indices of the state used to compute the comparison. This is particularly useful when the state space is large, and only a small number of states are used in the comparison function.
Below we describe a typical use case for infectious disease: given daily case counts during an epidemic, how can we estimate key features of the transmission process such as the transmission rate, recovery rate and from these the basic reproductive number \(R_0\).
Stochastic SIR model definition
A simple definition of the SIR model, as given in the odin documentation is: \[\begin{align*} \frac{dS}{dt} &= -\beta \frac{SI}{N} \\ \frac{dI}{dt} &= \beta \frac{SI}{N} - \gamma I \\ \frac{dR}{dt} &= \gamma I \\ \end{align*}\] \(S\) is the number of susceptibles, \(I\) is the number of infected and \(R\) is the number recovered; the total population size \(N = S + I + R\) is constant. \(\beta\) is the infection rate, \(\gamma\) is the recovery rate.
Discretising this model in time steps of width \(dt\) gives the following update equations for each time step:
\[\begin{align*} S_{t+1} &= S_t - n_{SI} \\ I_{t+1} &= I_t + n_{SI} - n_{IR} \\ R_{t+1} &= R_t + n_{IR} \end{align*}\]
where \[\begin{align*} n_{SI} &\sim B(S, 1 - e^{-\beta \frac{I}{N} \cdot dt}) \\ n_{IR} &\sim B(I, 1 - e^{-\gamma \cdot dt}) \end{align*}\]
This example is included with the dust package, and can be loaded with:
gen_sir <- dust::dust_example("sir")To learn how to implement this yourself, see the vignette over at odin.dust.
Inferring parameters with mcstate
Typically these models will be used in conjunction with observed data to infer the highest posterior density values for model parameters, most likely trajectories up to the present (nowcast), and make forecasts using these parameters. The mcstate package implements particle filter and pMCMC methods to make all of this this possible from dust models.
A comparison function is needed to define a likelihood, i.e. the probability of observing this trajectory, given the data. This is combined with a prior to generate a posterior distribution for each parameter, which in the SIR model gives the distribution of likely values for \(\beta\) and \(\gamma\).
This is straightforward for a deterministic model, but for a stochastic model over a long time-series, trajectories can quickly become inconsistent with the data, and the massive space of potential outcomes makes downstream sampling highly inefficient. mcstate therefore implements a particle filter, also known as sequential Monte Carlo (SMC), which runs multiple trajectories, and at each stage where data is available resamples them in proportion to their likelihood, keeping only those trajectories close to the data, and with likelihoods that are plausibly important parts of the posterior. Importantly, this technique produces an unbiased estimate of the likelihood for a given set of parameters.
The anatomy of an mcstate particle filter, as noted above, consists of three main components:
- A set of observations to fit the model to, generated using
mcstate::particle_filter_data(). - A model to fit, which must be a dust generator, either
dust::dust()orodin.dust::odin_dust(). - A comparison function, which is an R function which calculates the likelihood of the state given the data at one time point.
Model data
To demonstrate this, we will attempt to infer the parameters \(\beta\) and \(\gamma\) using daily case counts. In reality these counts would be measured, but here we have generated them from a single run of the model with seed = 2L, and added some constant noise proportional to the epidemic size:
incidence <- read.csv(system.file("sir_incidence.csv", package = "mcstate"))This can then be processed with mcstate::particle_filter_data() as follows, taking four update steps between every observation so that rate = 4. Generally increasing the rate will improve resolution, especially if rates of change between partitions are high, though at the expense of extra computation time. We also define a time interval between each update \(dt = \frac{1}{\mathrm(rate)}\):
dt <- 0.25
sir_data <- mcstate::particle_filter_data(data = incidence,
time = "day",
rate = 1 / dt)
#> Warning in mcstate::particle_filter_data(data = incidence, time = "day", :
#> 'initial_time' should be provided. I'm assuming '0' which is one time unit
#> before the first time in your data (1), but this might not be appropriate. This
#> will become an error in a future version of mcstate
rmarkdown::paged_table(sir_data)
plot(incidence$day, incidence$cases,
type = "l", xlab = "Day", ylab = "New cases")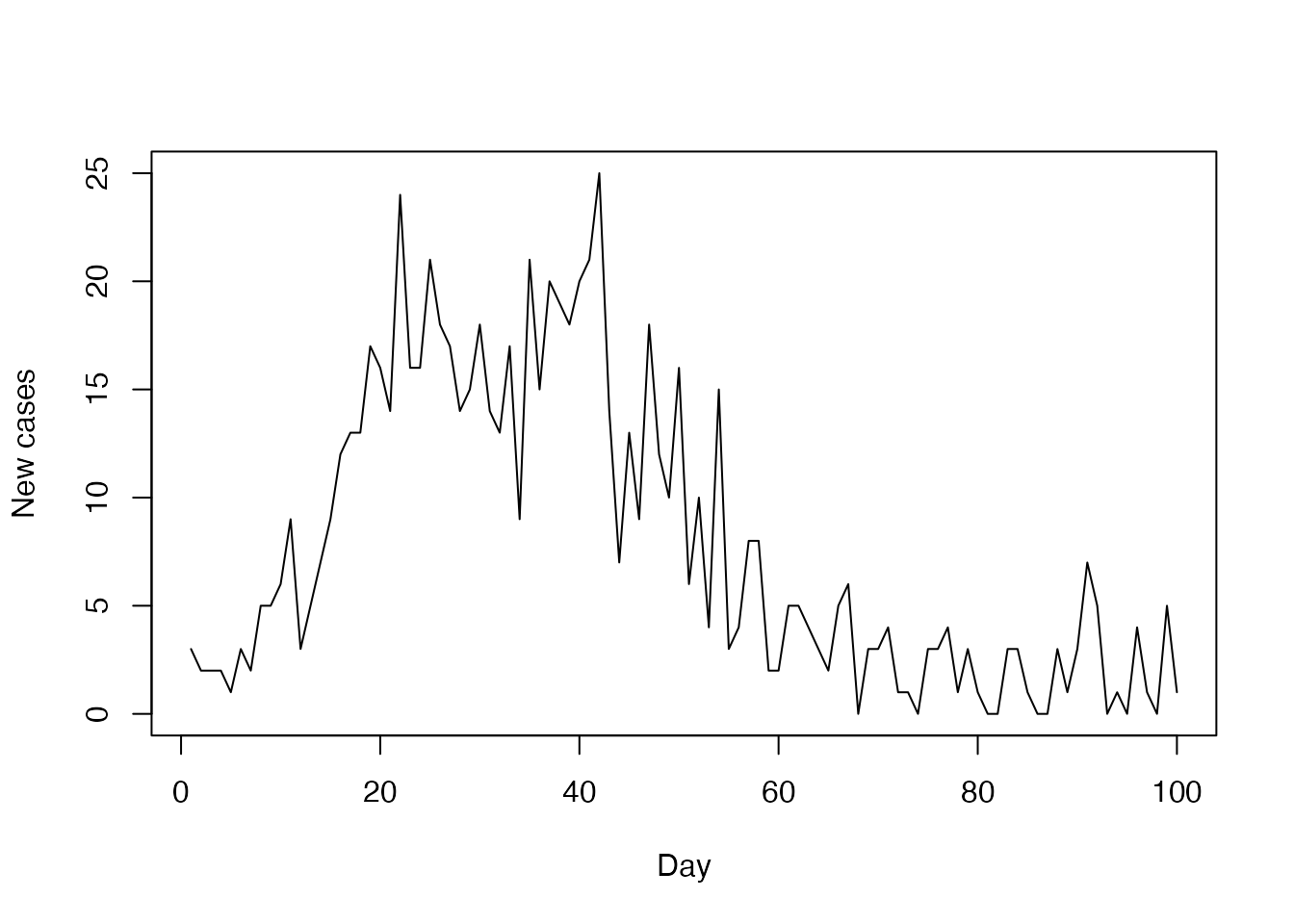
More complex models may have additional data streams added as further columns (e.g. deaths, hospital admissions). This will be fed as observed data to the compare function, which will combine and compute the evidence for the current model state.
Defining the comparison function
The comparison function will typically be a likelihood, the probability of the simulation run given the data. This can be any function in R which takes the current simulated state, a data row for the current time point and a list of any parameters pars the function needs.
For this model the daily number of cases is calculated within update function and returned as the 5th state element. In this comparison function, the number of cases within each time interval is modelled as being Poisson distributed. A small amount of noise is added to prevent zero expectations.
case_compare <- function(state, observed, pars = NULL) {
exp_noise <- 1e6
incidence_modelled <- state[5, , drop = TRUE]
incidence_observed <- observed$cases
lambda <- incidence_modelled +
rexp(n = length(incidence_modelled), rate = exp_noise)
dpois(x = incidence_observed, lambda = lambda, log = TRUE)
}We can use the info() method on a dust model to inspect what order the state variables will come in:
gen_sir$new(pars = list(), time = 0, n_particles = 1L)$info()
#> $vars
#> [1] "S" "I" "R" "cases_cumul" "cases_inc"
#>
#> $pars
#> $pars$beta
#> [1] 0.2
#>
#> $pars$gamma
#> [1] 0.1The SIR example actually outputs incidence directly as part of the state, so the comparison function can be written without needing to recalculate this:
incidence_compare <- function(state, prev_state, observed, pars = NULL) {
exp_noise <- 1e6
lambda <- state[4, , drop = TRUE] +
rexp(n = length(incidence_modelled), rate = exp_noise)
dpois(x = observed$cases, lambda = lambda, log = TRUE)
}Just some of the state can be extracted for the comparison function, which is demonstrated below.
Inferring parameters
Using these pieces, we can set up a particle filter as follows:
n_particles <- 100
filter <- mcstate::particle_filter$new(data = sir_data,
model = gen_sir,
n_particles = n_particles,
compare = case_compare,
seed = 1L)We can now run the particle filter forward, which will run and resample 100 trajectories, and return the final likelihood. It is important to set the correct time-step dt here, as we are using 0.25, rather than the default value of 1 defined in the odin model. We will also save the history, which allows us to plot the particle trajectories, as well as use the likelihood:
filter$run(save_history = TRUE, pars = list(dt = dt))
#> [1] -243.511If we plot these along with the data, we can see compared to above that only trajectories consistent with the data are kept, and the variance between particles has been reduced compared to the simulations shown in the odin.dust vignette:
plot_particle_filter <- function(history, true_history, times, obs_end = NULL) {
if (is.null(obs_end)) {
obs_end <- max(times)
}
par(mar = c(4.1, 5.1, 0.5, 0.5), las = 1)
cols <- c(S = "#8c8cd9", I = "#cc0044", R = "#999966")
matplot(times, t(history[1, , -1]), type = "l",
xlab = "Time", ylab = "Number of individuals",
col = cols[["S"]], lty = 1, ylim = range(history))
matlines(times, t(history[2, , -1]), col = cols[["I"]], lty = 1)
matlines(times, t(history[3, , -1]), col = cols[["R"]], lty = 1)
matpoints(times[1:obs_end], t(true_history[1:3, , -1]), pch = 19,
col = cols)
legend("left", lwd = 1, col = cols, legend = names(cols), bty = "n")
}
true_history <- readRDS("sir_true_history.rds")
plot_particle_filter(filter$history(), true_history, incidence$day)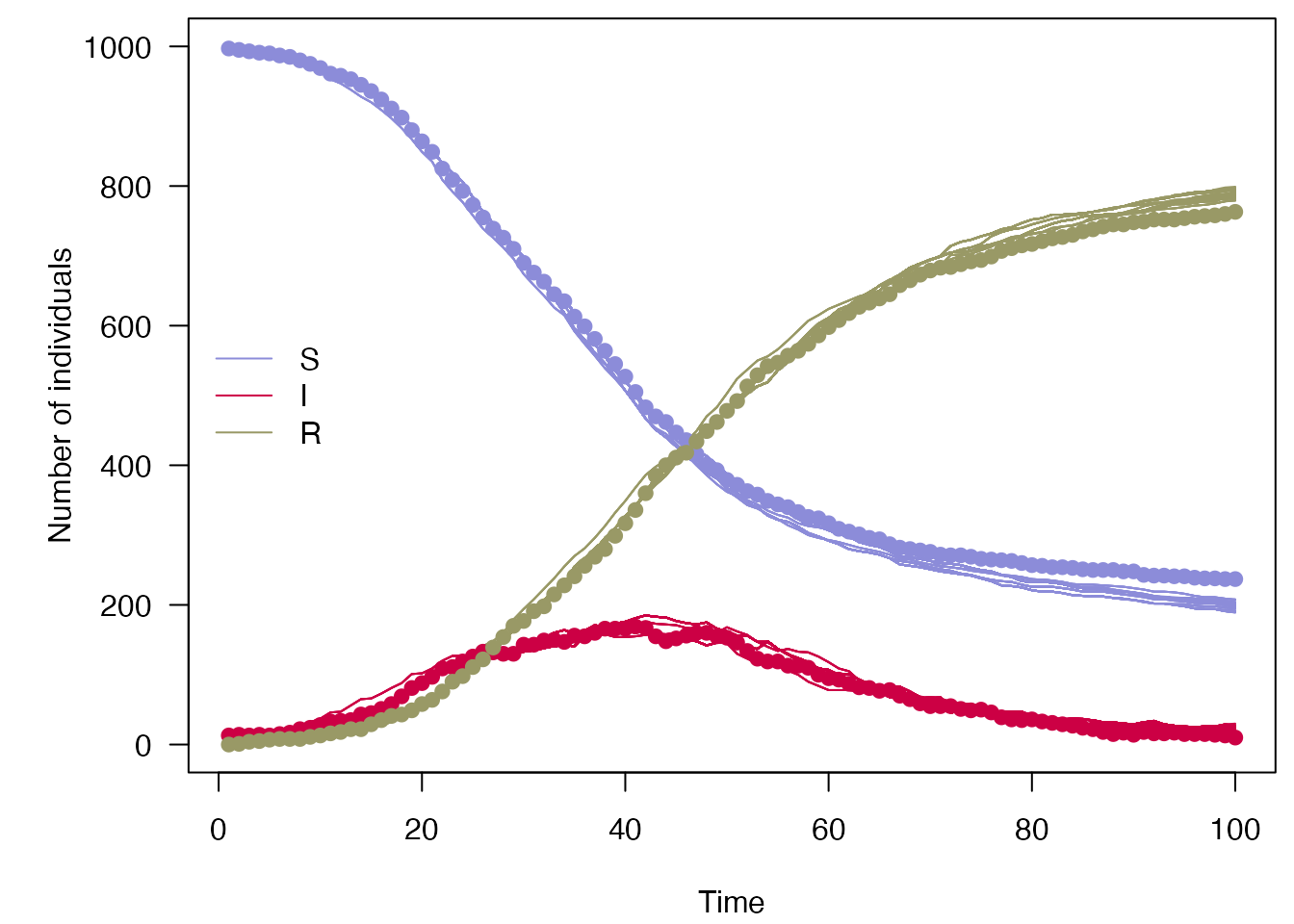
Doing the same with a \(\beta\) and \(\gamma\) which are further from the truth yields a lower likelihood:
filter$run(save_history = TRUE, pars = list(dt = dt, beta = 0.4, gamma = 0.2))
#> [1] -257.304
plot_particle_filter(filter$history(), true_history, incidence$day)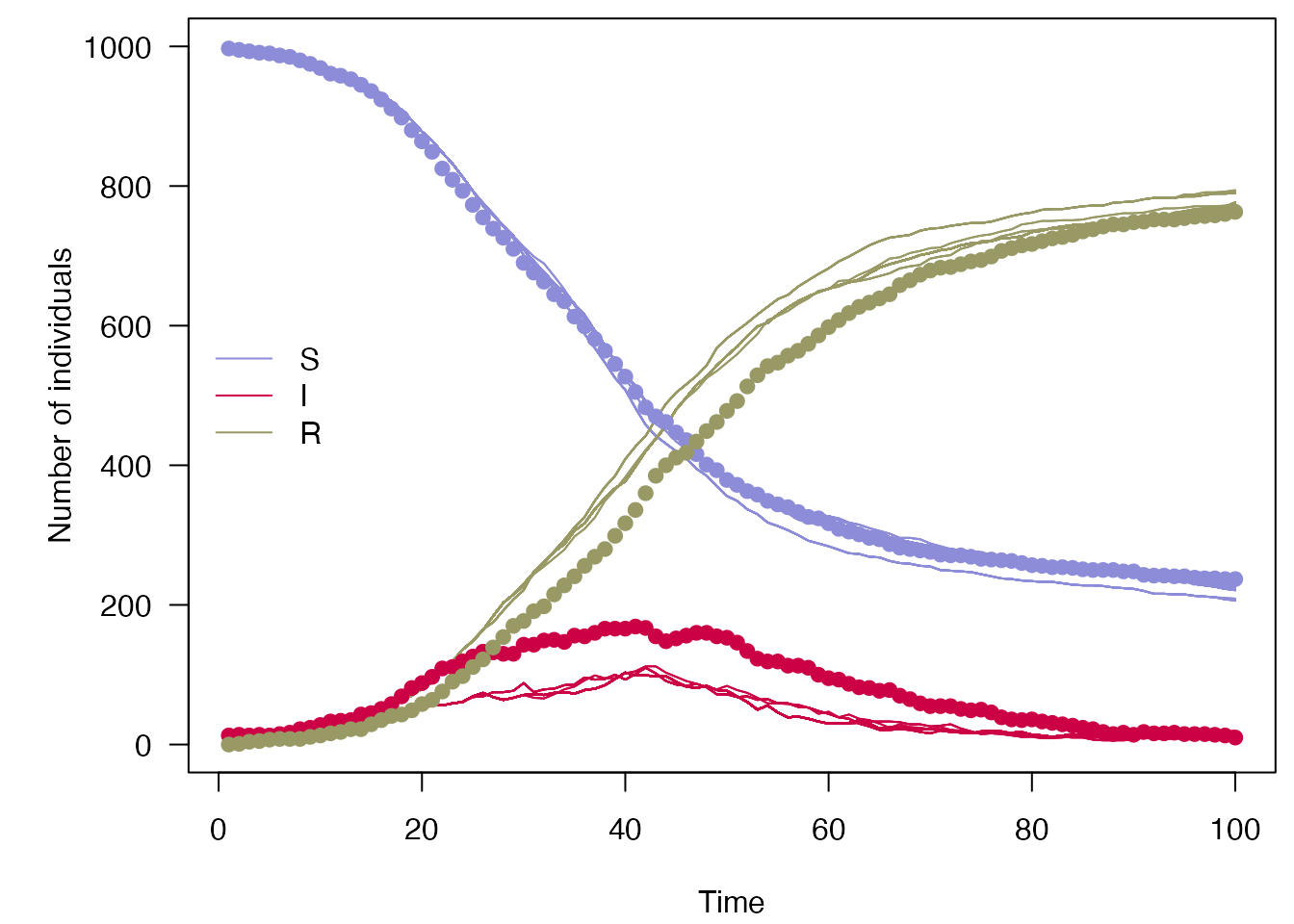
You can use the run() function of the particle filter directly, but for parameter inference, or forecasting after parameter inference, you should usually use the functions below to infer parameters.
Using MCMC to infer parameters
Using this, we can do a MCMC using the Metropolis-Hastings algorithm to infer the values of \(\beta\) and \(\gamma\) from daily case counts. Let’s first describe the parameters we wish to infer, giving a minimum, maximum. For \(\gamma\) we will also apply a gamma prior with shape 1 and rate 0.2: \(\Gamma(1, 0.2)\):
beta <- mcstate::pmcmc_parameter("beta", 0.2, min = 0)
gamma <- mcstate::pmcmc_parameter("gamma", 0.1, min = 0, prior = function(p)
dgamma(p, shape = 1, scale = 0.2, log = TRUE))
proposal_matrix <- diag(0.1, 2)
mcmc_pars <- mcstate::pmcmc_parameters$new(list(beta = beta, gamma = gamma),
proposal_matrix)The proposals for each MCMC step are also set here. Proposals are drawn from a multi-variate normal distribution, with the variance-covariance matrix set here. In this case we have simply set \(\beta_{n+1} \sim N(\beta_{n}, 0.01)\) and \(\gamma_{n+1} \sim N(\gamma_{n}, 0.01)\) so there is no covariance. We show how to improve this below.
Note that in this very simple case, the parameters that our model takes as input (alpha and beta) happen to be exactly the same as the ones that we are interested in inferring. For nontrivial models this is very unlikely to the case, see the section “Parameter transformations” in ?mcstate::pmcmc_parameter for details on how to cope with this.
The sampler can now be run using these parameters, and the particle filter defined above.
n_steps <- 500
n_burnin <- 200Taking 500 steps on a single chain:
control <- mcstate::pmcmc_control(
n_steps,
save_state = TRUE,
save_trajectories = TRUE,
progress = TRUE)
pmcmc_run <- mcstate::pmcmc(mcmc_pars, filter, control = control)
#> Running chain 1 / 1
#> Finished 500 steps in 4 secs
plot_particle_filter(pmcmc_run$trajectories$state, true_history, incidence$day)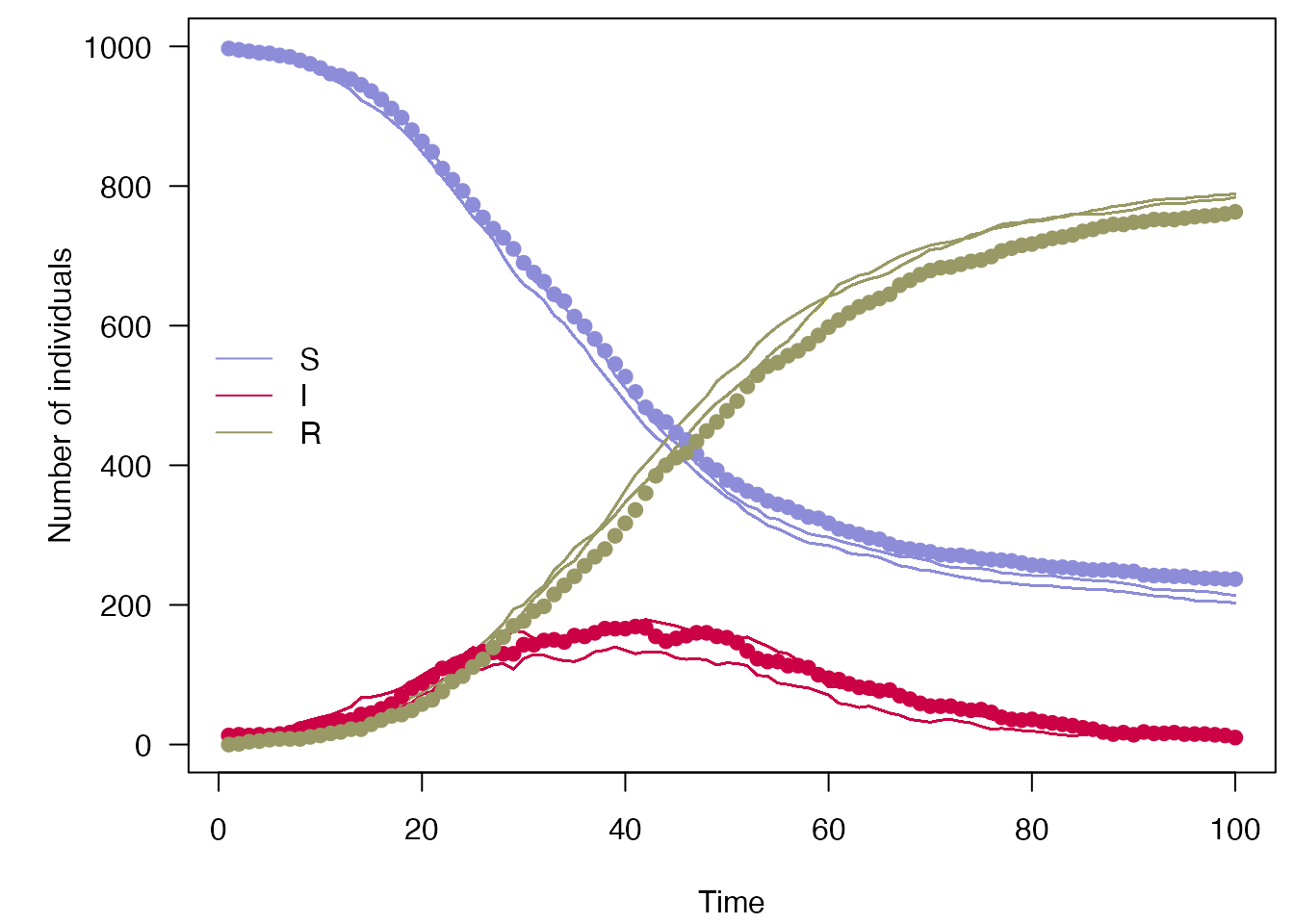
We also provide some basic tools for dealing with this output, before running prediction (see below). We can remove burn-in and thin the four chains as follows:
processed_chains <- mcstate::pmcmc_thin(pmcmc_run, burnin = n_burnin, thin = 2)
parameter_mean_hpd <- apply(processed_chains$pars, 2, mean)
parameter_mean_hpd
#> beta gamma
#> 0.2069454 0.1044010The resulting objects can also be analysed in a typical MCMC analysis package such as coda. We will need to combine the two parts of the object which contain the probabilities and parameter values across the iterations:
mcmc1 <- coda::as.mcmc(cbind(pmcmc_run$probabilities, pmcmc_run$pars))
summary(mcmc1)
#>
#> Iterations = 1:500
#> Thinning interval = 1
#> Number of chains = 1
#> Sample size per chain = 500
#>
#> 1. Empirical mean and standard deviation for each variable,
#> plus standard error of the mean:
#>
#> Mean SD Naive SE Time-series SE
#> log_prior 1.0962 0.040556 0.0018137 0.017605
#> log_likelihood -245.9326 0.321585 0.0143817 0.139599
#> log_posterior -244.8363 0.362141 0.0161954 0.157204
#> beta 0.2042 0.012801 0.0005725 0.005557
#> gamma 0.1026 0.008111 0.0003627 0.003521
#>
#> 2. Quantiles for each variable:
#>
#> 2.5% 25% 50% 75% 97.5%
#> log_prior 0.9719 1.109 1.109 1.109 1.1094
#> log_likelihood -246.9184 -245.828 -245.828 -245.828 -245.8279
#> log_posterior -245.9465 -244.718 -244.718 -244.718 -244.7184
#> beta 0.2000 0.200 0.200 0.200 0.2434
#> gamma 0.1000 0.100 0.100 0.100 0.1275
plot(mcmc1)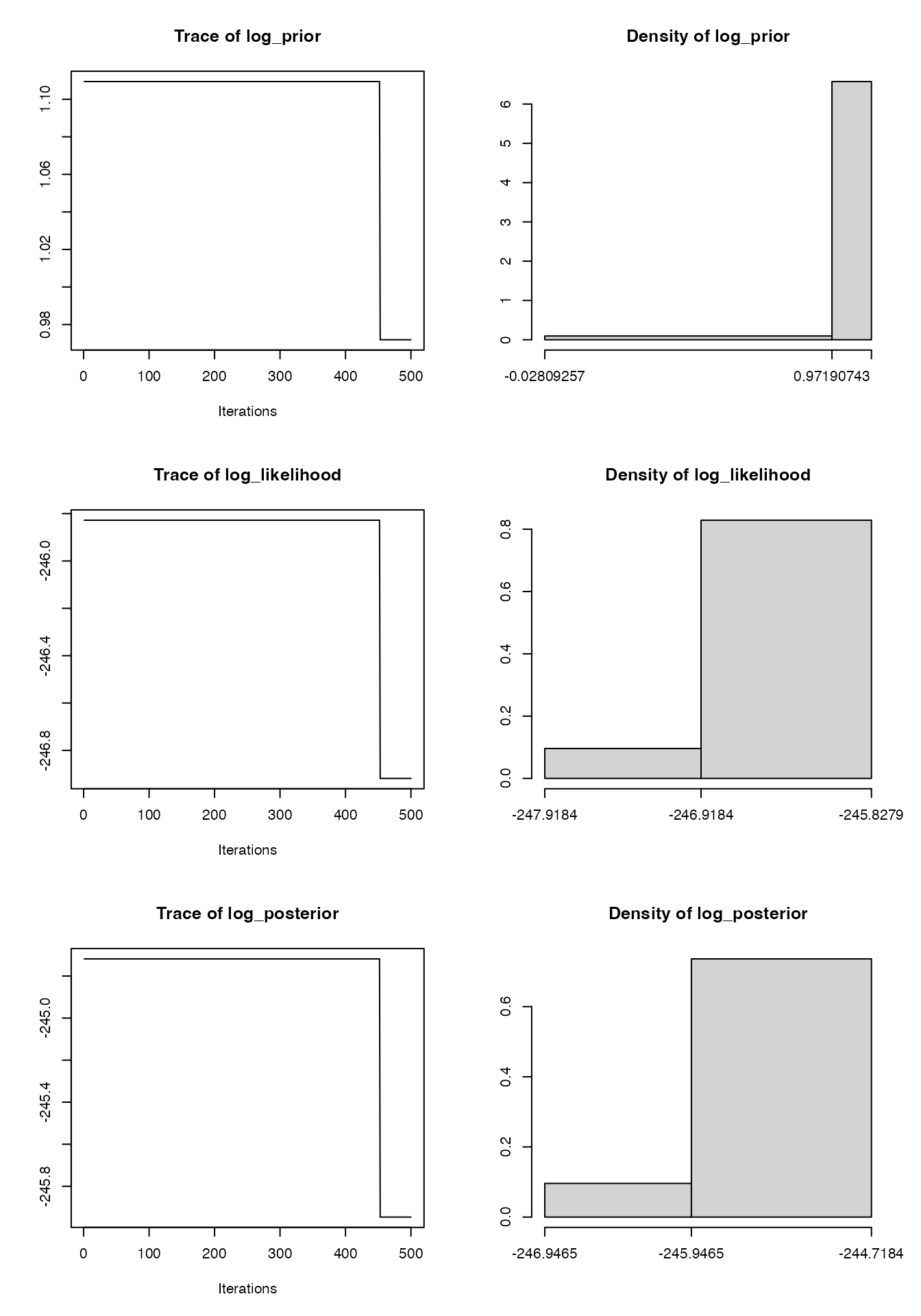
Tuning the pMCMC
The MCMC above is not particularly efficient in terms of effective sample size per iteration:
coda::effectiveSize(mcmc1)
#> log_prior log_likelihood log_posterior beta gamma
#> 5.306729 5.306729 5.306729 5.306729 5.306729
1 - coda::rejectionRate(mcmc1)
#> log_prior log_likelihood log_posterior beta gamma
#> 0.002004008 0.002004008 0.002004008 0.002004008 0.002004008Clearly the acceptance rate is too low. Generally a target of 0.5, reducing to 0.234 as the number of parameters increases, is thought to be optimal. The proposal distribution needs to be modified, in this case reducing the variance of the jump sizes. One option to automate this process is to run a chain for a bit, as above, then use the covariance of the state as the proposal matrix:
proposal_matrix <- cov(pmcmc_run$pars)
mcmc_pars <- mcstate::pmcmc_parameters$new(
list(beta = beta, gamma = gamma),
proposal_matrix)
proposal_matrix
#> beta gamma
#> beta 0.0001638582 1.038287e-04
#> gamma 0.0001038287 6.579108e-05Let’s now run four independent chains with these proposals:
control <- mcstate::pmcmc_control(
n_steps,
save_state = TRUE,
save_trajectories = TRUE,
progress = TRUE,
n_chains = 4)
pmcmc_tuned_run <- mcstate::pmcmc(mcmc_pars, filter, control = control)
#> Running chain 1 / 4
#> Finished 500 steps in 5 secs
#> Running chain 2 / 4
#> Finished 500 steps in 5 secs
#> Running chain 3 / 4
#> Finished 500 steps in 4 secs
#> Running chain 4 / 4
#> Finished 500 steps in 4 secs
mcmc2 <- coda::as.mcmc(cbind(
pmcmc_tuned_run$probabilities, pmcmc_tuned_run$pars))
summary(mcmc2)
#>
#> Iterations = 1:2000
#> Thinning interval = 1
#> Number of chains = 1
#> Sample size per chain = 2000
#>
#> 1. Empirical mean and standard deviation for each variable,
#> plus standard error of the mean:
#>
#> Mean SD Naive SE Time-series SE
#> log_prior 1.0735 0.07407 0.0016561 0.008987
#> log_likelihood -244.1987 1.11305 0.0248886 0.083031
#> log_posterior -243.1252 1.12001 0.0250441 0.084039
#> beta 0.2113 0.02338 0.0005227 0.002837
#> gamma 0.1072 0.01481 0.0003312 0.001797
#>
#> 2. Quantiles for each variable:
#>
#> 2.5% 25% 50% 75% 97.5%
#> log_prior 0.93688 1.01925 1.0709 1.1310 1.2168
#> log_likelihood -246.74188 -244.85765 -244.0475 -243.4730 -242.2685
#> log_posterior -245.64671 -243.78390 -243.0167 -242.3229 -241.1562
#> beta 0.16611 0.19320 0.2122 0.2285 0.2545
#> gamma 0.07852 0.09569 0.1077 0.1180 0.1345
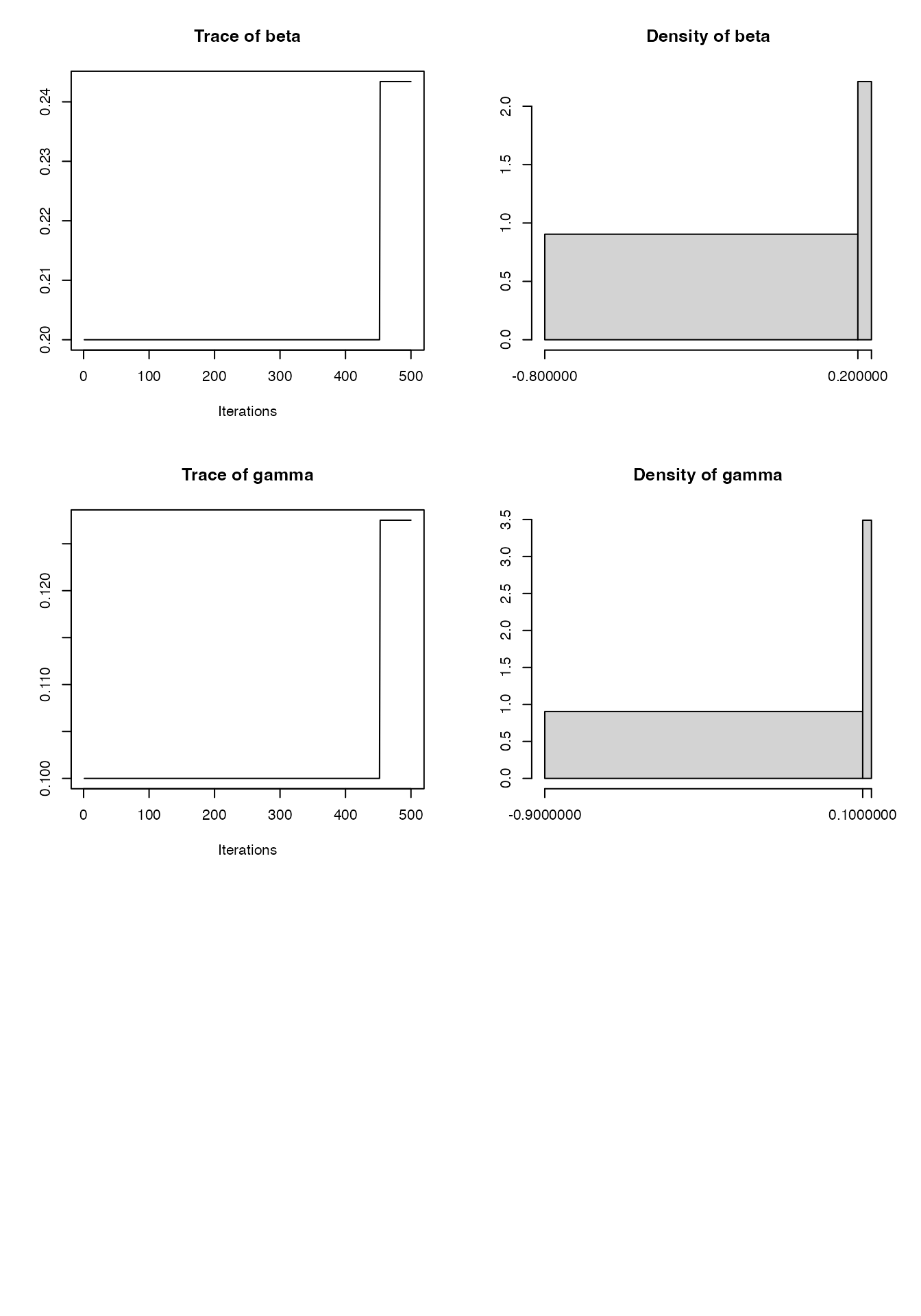
plot(mcmc2)

Looking again at the effective sample size and rejection rate, these chains were a lot more efficient, and have a much better effective sample size thanks for the four chains:
coda::effectiveSize(mcmc2)
#> log_prior log_likelihood log_posterior beta gamma
#> 67.9180 179.6991 177.6126 67.9180 67.9180
1 - coda::rejectionRate(mcmc2)
#> log_prior log_likelihood log_posterior beta gamma
#> 0.4142071 0.4142071 0.4142071 0.4142071 0.4142071Running predictions
Going back to the simple SIR model above, we can easily continue running the fitted model forward in time using the posterior estimated by pmcmc() to create a forecast past the end of the data, sampling 10 particles:
## TODO: the use of times here is confusing, which is it?
forecast <- predict(processed_chains,
times = seq(400, 800, 4),
prepend_trajectories = TRUE,
seed = processed_chains$predict$seed)
keep <- sample.int(ncol(forecast$state), size = 10)
mini_forecast <- forecast$state[, keep, ]
plot_particle_filter(mini_forecast,
true_history,
seq_len(200),
obs_end = max(incidence$day))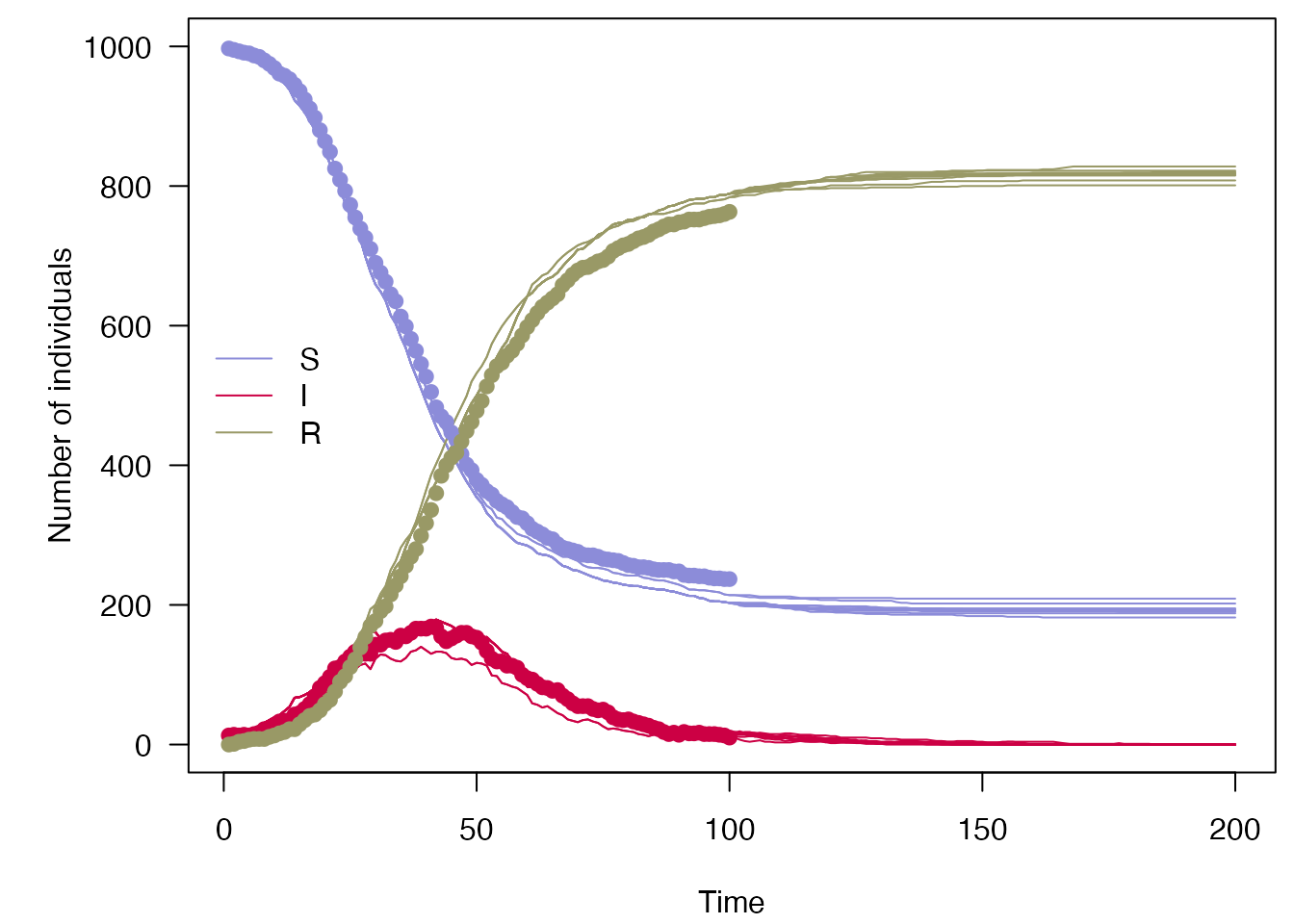
Up to \(t = 100\) is the nowcast, from \(t = 100\) to \(t = 200\) is the forecast.
Fitting to multiple datastreams
The set up of the particle filter and observation function makes it easy to fit to multiple datastreams within a Bayesian framework. Let us model a disease where a proportion of infected cases \(p_{\mathrm{death}} = 0.05\) die rather than recover by adding the following lines to the odin code:
## Definition of the time-step and output as "time"
steps_per_day <- user(1)
dt <- 1 / steps_per_day
initial(time) <- 0
update(time) <- (step + 1) * dt
## Core equations for transitions between compartments:
update(S) <- S - n_SI
update(I) <- I + n_SI - n_IR - n_ID
update(R) <- R + n_IR
update(D) <- D + n_ID
## Individual probabilities of transition:
p_SI <- 1 - exp(-beta * I / N) # S to I
p_IR <- 1 - exp(-gamma) # I to R
## Draws from binomial distributions for numbers changing between
## compartments, dealing competing hazards for I -> R and I -> D
n_Ix <- rbinom(I, p_IR * dt)
n_IR <- rbinom(n_Ix, 1 - p_death)
n_ID <- n_Ix - n_IR
n_SI <- rbinom(S, p_SI * dt)
## Total population size
N <- S + I + R
## Initial states:
initial(S) <- S_ini
initial(I) <- I_ini
initial(R) <- 0
initial(D) <- 0
## Convert some cumulative values into incidence:
initial(S_inc) <- 0
initial(D_inc) <- 0
update(S_inc) <- if (step %% steps_per_day == 0) n_SI else S_inc + n_SI
update(D_inc) <- if (step %% steps_per_day == 0) n_ID else D_inc + n_ID
## User defined parameters - default in parentheses:
S_ini <- user(1000)
I_ini <- user(10)
beta <- user(0.2)
gamma <- user(0.1)
p_death <- user(0.05)Creating a model from this code:
gen_death <- odin.dust::odin_dust("deaths.R", verbose = FALSE)
#> Loading required namespace: pkgbuildWe can simulate some data to fit to, as before. We have also made the case data patchy, so it is missing on some days:
dt <- 0.25
death_data <- read.table("death_data.csv", header = TRUE, sep = ",")
true_history_deaths <- readRDS("deaths_true_history.rds")
combined_data <- mcstate::particle_filter_data(
death_data,
time = "day",
rate = 1 / dt
)
#> Warning in mcstate::particle_filter_data(death_data, time = "day", rate =
#> 1/dt): 'initial_time' should be provided. I'm assuming '0' which is one time
#> unit before the first time in your data (1), but this might not be appropriate.
#> This will become an error in a future version of mcstate
rmarkdown::paged_table(combined_data)We then need to add this into our comparison function, and in doing so we will also demonstrate the use of the index parameter for the particle filter.
For models with a very large state space returning only those states required by the comparison function can be important for efficiency. The only model outputs needed from the comparison function are \(S_inc\) and \(D_inc\), i.e. the number of new cases and deaths. So, an index function to extract just this part of the state can be defined, which operates on dust generators info():
index <- function(info) {
list(run = c(cases = info$index$S_inc,
deaths = info$index$D_inc),
state = c(S = info$index$S,
I = info$index$I,
R = info$index$R,
D = info$index$D))
}
death_model <- gen_death$new(pars = list(), time = 0, n_particles = 1L)
index(death_model$info())
#> $run
#> cases deaths
#> 6 7
#>
#> $state
#> S I R D
#> 2 3 4 5The index function sends the comparison function the indices listed under run, in this case the number of new cases and deaths, and saves any compartments listed under state if the history is kept. If the run and state vectors have named entries, these names will be passed to the particle filter, making it simple to refer to the model states in the comparison function and in the state history. In the comparison function, missing data must be checked for and must contribute 0 to the likelihood if found:
# log-likelihood of Poisson count
ll_pois <- function(obs, model) {
exp_noise <- 1e6
if (is.na(obs)) {
# Creates vector of zeros in ll with same length, if no data
ll_obs <- numeric(length(model))
} else {
lambda <- model +
rexp(n = length(model), rate = exp_noise)
ll_obs <- dpois(x = obs, lambda = lambda, log = TRUE)
}
ll_obs
}
# Sum log likelihoods from each datastream
combined_compare <- function(state, observed, pars = NULL) {
ll_cases <- ll_pois(observed$cases, state["cases", , drop = TRUE])
ll_deaths <- ll_pois(observed$deaths, state["deaths", , drop = TRUE])
ll_cases + ll_deaths
}The comparison and index() functions can be used to set up a particle filter as before, which now has a named history:
n_particles <- 100L
filter <- mcstate::particle_filter$new(data = combined_data,
model = gen_death,
n_particles = n_particles,
compare = combined_compare,
index = index,
seed = 1L)
filter$run(save_history = TRUE, pars = list(dt = dt))
#> [1] -1479.164
dimnames(filter$history())
#> [[1]]
#> [1] "S" "I" "R" "D"
#>
#> [[2]]
#> NULL
#>
#> [[3]]
#> NULLThis filter can be used to run the pmcmc() method, as above.