We support one cluster at present (the DIDE cluster), which supports running jobs on Windows and Linux nodes. We may add support for other clusters in the future. We particular want to allow submitting jobs to the central ICT/RCS Linux cluster via PBS, and if there is a need for our own pure Linux cluster (as opposed to our MS-HPC hybrid), we may try and create our own SLURM-based system.
This vignette collects instructions specific to our DIDE cluster running on either Windows or Linux; the commands are the same for either, but there are inevitably some differences concerning paths which we’ll describe below.
Pre-requisites:-
In short, you will need:
- to know your DIDE username and password
- to have been added as a DIDE cluster user
- to be connected to the DIDE network, (probably using ZScaler)
- to have as your working directory a network share that the cluster can see
These are all explained in detail below. Once these are all
satisfied, you can initialise hipercow using
hipercow_init() use dide_check() to verify
everything works, and hipercow_hello() to submit a test
task.
Authentication with DIDE
First run the dide_authenticate() function which will
talk you through entering your credentials and checking that they work.
You only need to do this once per machine, each time you change your
password.
A typical interaction with this looks like:
> dide_authenticate()
I need to unlock the system keychain in order to load and save
your credentials. This might differ from your DIDE password,
and will be the password you use to log in to this particular
machine
Keyring password:
🔑 OK
── Please enter your DIDE credentials ──────────────────────────
We need to know your DIDE username and password in order to log
you into the cluster. This will be shared across all projects
on this machine, with the username and password stored securely
in your system keychain. You will have to run this command
again on other computers
Your DIDE password may differ from your Imperial password, and
in some cases your username may also differ. If in doubt,
perhaps try logging in at https://mrcdata.dide.ic.ac.uk/hpc and
use the combination that works for you there.
DIDE username (default: rfitzjoh) >
Password:
🔑 OK
I am going to try and log in with your password now, if this
fails we can always try again, as failure is just the first
step towards great success.
Excellent news! Everything seems to work!If you hit problems, try going to https://mrcdata.dide.ic.ac.uk/hpc and trying a few combinations until you remember what it should be. Once done update this in your password manager (perhaps BitWarden?) so you can find it easily next time.
It is possible that you do not have access to the cluster, even if your username is correct. Try logging onto the portal; if it reports that you don’t have access then please request access by messaging Wes. If you don’t know your username and password, read on.
About our usernames and passwords
For historical reasons DIDE exists on its own domain (DIDE) separate from Imperial’s domain (IC). This means that you may have a different DIDE username to your Imperial username (though usually the same) and you may have a different password (though most people set these to be the same).
The overall situation is summarised in this infographic:
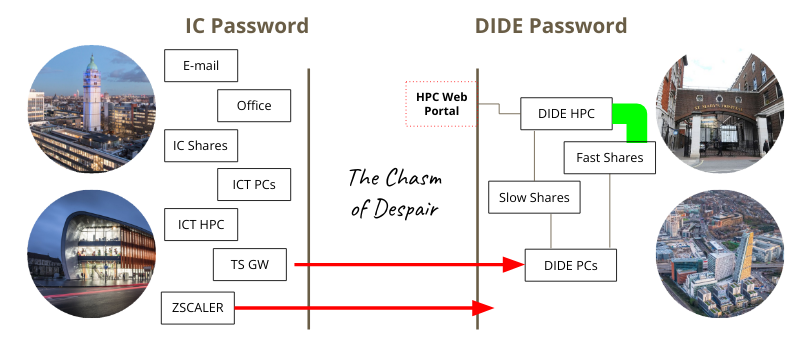
If you need to change your DIDE password you can do this from any DIDE domain machine by pressing Ctrl-Alt-Delete and following the prompts. If it has already expired, such that you can’t login, you need to contact Chris or Paul.
We store credentials using the keyring package. This saves your
username and password securely in your system keyring, which will be
unlocked on login for at least Windows and macOS. You will need to rerun
dide_authenticate() whenever you change your DIDE
password.
Linux users may have to install some additional system packages (on
Ubuntu/Debian etc this is libsecret-1-dev,
libssl-dev, and libsodium-dev) or you will
have to enter your keychain password each time you use
hipercow.
Networks
Ensure you have connected to the DIDE network by using ZScaler; see instructions from ICT, or by being on a desktop PC or virtual machine within the building that is plugged in by Ethernet (this is less common now). Note that being connected to the WiFi in the building is not enough - you will need ZScaler.
Filesystems and paths
For anything to work with hipercow on the DIDE cluster,
your working directory must be on a network share. If you are not sure
if you are on a network share, then run
getwd()Interpreting this depends on your platform (the machine you are typing commands into):
-
Windows: A drive like
C:orD:will be local. You should recognise the drive letter as one likeQ:that was mapped by default as your home orM:that you mapped yourself as a project share. -
macOS: The path will likely be below
/Volumes(but not one that corresponds to a USB stick of course!) -
Linux: The path should start at one of the mount
points you have configured in
/etc/fstabas a network path.
Cluster-based storage and home directories
We strongly recommend that you use cluster-based
storage for any serious work. The servers hosting these shares start
with wpia-hn, and you should use those rather than your
home directory (servers called qdrive, or
wpia-san04), or the temp drive or other departmental
project shares (servers starting with wpia-didef4 or
projects).
The advantages of the cluster-based shares are that they are larger
(so you will run out of disk space more slowly) and faster than the
others. If you launch many tasks at once that use your home share you
can get unexpected failures as the disk can’t keep up with the amount of
data being read and written. Don’t use your home directory (generally
Q: on Windows) for anything more intensive than casual
experimentation. We have seen many people with jobs that fail
mysteriously on their network home directory when launched in parallel,
and this is generally fixed by using the cluster share.
If you don’t know if you have access to a cluster-based share, talk to your PI about if one exists for you. If you are a PI, talk to Chris (and/or Wes) about getting one set up.
Mapping network drives on your computer
For all operating systems, you will need to be connected to the DIDE departmental domain. Options are:-
- From outside the department, using ZScaler see the ICT documentation for details.
- From inside the department on the wifi, you also need ZScaler connected.
- From inside the department on the wired network. This is the fastest and most stable network, giving the best experience if it is available to you.
Below, instructions for setting up depend on the sort of computer you are typing commands into at the moment (not the cluster type). We’re going to use the example of mapping your home directory up; as we said earlier, this isn’t recommended for proper cluster running, but everyone should have a home share, so we can use it as an example.
Windows
If you are using a Windows machine in the DIDE domain, then your home drive (Q:) and the temp drive (T:) will likely already be mapped for you. You cannot have a fully-qualified network name as your current working directory, so although Windows can load files from a fully-qualified network name, the results are not always as you might hope.
So if you need to map another drive, or if you’re not in the DIDE domain, then:-
- If not on DIDE domain, fire up ZScaler (with your IC credentials)
- Open This PC, and under the Computer tab, find Map network drive.
- That drops down to reveal another Map network drive button.
- Choose a drive letter - which is arbitrary, the conventions are
Q:for your home drive,T:for the temp drive. Please avoid usingI:as we use this for Hipercow internally, and anything beforeD:is likely to clash with your system. - Set the fully-qualified network share; for example
\\qdrive.dide.ic.ac.uk\homes\bob - Tick “Connect using different credentials”, and “Reconnect at sign-in”.
- Click Finish, and then in the credentials window, choose “More choices”, “Use a different account”.
- Specify your username including the domain -
DIDE\bobfor example, and your DIDE password. - Choose “Remember me” if you’re happy to, and then “OK” and the drive should get mapped.
macOS
In Finder, go to Go -> Connect to Server... or press
Command-K. In the address field write the name of the share
you want to connect to. If your DIDE username is bob,
you’ll write:
smb://qdrive.dide.ic.ac.uk/homes/bobwhich will work only for Bob’s home share. You will get a message saying “You are attempt to connect to the server”qdrive.dide.ic.ac.uk” and you press Connect to continue.
After that, the credentials page, and you’ll select Registered
User (not guest), your username, for example DIDE\bob
and you’ll provide your DIDE password. You may like to tick “Remember
this password” if you’re happy to.
This directory will be mounted at /Volumes/bob - that
is, the last folder of the fully-qualified domain name you provide
becomes the name of the local mountpoint within /Volumes).
There may be a better way of doing this, and the connection will not be
re-established automatically so if anyone has a better way let us
know.
Linux
This is our current understanding of the best way. Full instructions are on the Ubuntu community wiki.
First, install cifs-utils
sudo apt-get install cifs-utilsIn your /etc/fstab file, add
//qdrive.dide.ic.ac.uk/homes/<dide-username> <home-mount-point> cifs uid=<local-userid>,gid=<local-groupid>,credentials=/home/<local-username>/.smbcredentials,domain=DIDE,sec=ntlmssp,iocharset=utf8 0 0where:
-
<dide-username>is your DIDE username without theDIDE\bit. -
<local-username>is your local username (i.e.,echo $USER). -
<local-userid>is your local numeric user id (i.e.id -u $USER) -
<local-groupid>is your local numeric group id (i.e.id -g $USER) -
<home-mount-point>is where you want your DIDE home directory mounted
please back this file up before editing.
This is an example from Rich - his local Linux user is
rich, and his DIDE username is rfitzjoh, and
the uid and gid were looked up as above:-
//qdrive.dide.ic.ac.uk/homes/rfitzjoh /home/rich/net/home cifs uid=1000,gid=1000,credentials=/home/rich/.smbcredentials,domain=DIDE,sec=ntlmssp,iocharset=utf8 0 0The file .smbcredentials contains
username=<dide-username>
password=<dide-password>and set this to be chmod 600 for a modicum of security, but be aware your password is stored in plaintext.
This set up is clearly insecure. I believe if you omit the credentials line you can have the system prompt you for a password interactively, but I’m not sure how that works with automatic mounting.
Finally, run
sudo mount -ato mount all drives and with any luck it will all work and you don’t have to do this until you get a new computer.
If you are on a laptop that will not regularly be connected to the
internal network, you might want to add the option noauto
to the above
//qdrive.dide.ic.ac.uk/homes/rfitzjoh /home/rich/net/home cifs uid=1000,gid=1000,credentials=/home/rich/.smbcredentials,domain=DIDE,sec=ntlmssp,iocharset=utf8,noauto 0 0and then explicitly mount the drive as required with
sudo mount ~/net/homeInitialisation
For most use, it will be sufficient to write this if, for example you want to run jobs on Windows nodes.
library(hipercow)
hipercow_init()
#> ✔ Initialised hipercow at '.' (/home/rfitzjoh/net/home/cluster/hipercow-vignette/hv-20250423-7d83f6872b6bb)
#> ℹ Next, call 'hipercow_configure()'
hipercow_configure(driver = "dide-windows")
#> ✔ Configured hipercow to use 'dide-windows'Instead, or additionally, you could configure with
dide-linux to indicate you’d like to run jobs on Linux
nodes. Configuring both drivers is fine if for this project you may want
to launch on both platforms. If you configure both, you’ll have to be
specific about which you want to use for provisioning and task creation,
whereas if there’s only one driver, it will be used by default. So see
which workflow you prefer, whether both from the same root, or keeping
things separate. The examples in the vignettes assume only one driver is
configured, so you won’t see the driver argument explicitly
set.
One more thing: if you are only using a single driver, then you can
combine the init and configure into, for
example, hipercow_init("dide-windows").
By default, we aim to automatically detect your shares, and we believe this works on Windows, macOS and Linux. If you are running on a network share and the configuration errors because it cannot work out what share you are on, please let us know.
Does it work?
All the above steps can be checked automatically:
library(hipercow)
hipercow_init(driver = "dide-windows")
#> ℹ hipercow already initialised at '.' (/home/rfitzjoh/net/home/cluster/hipercow-vignette/hv-20250423-7d83f6872b6bb)
#> ℹ Configuration for 'dide-windows' unchanged
dide_check()
#> ✔ Found DIDE credentials for 'rfitzjoh'
#> ✔ DIDE credentials are correct
#> ✔ Connection to private network working
#> ✔ Path looks like it is on a network share
#> ℹ Using '/home/rfitzjoh/net/home/cluster/hipercow-vignette/hv-20250423-7d83f6872b6bb'
#> ✔ 'hipercow' and 'hipercow.dide' versions agree (1.1.3)Try a test task:
hipercow_hello()
#> ✔ Found DIDE credentials for 'rfitzjoh'
#> ✔ DIDE credentials are correct
#> ✔ Connection to private network working
#> ✔ Path looks like it is on a network share
#> ℹ Using '/home/rfitzjoh/net/home/cluster/hipercow-vignette/hv-20250423-7d83f6872b6bb'
#> ✔ 'hipercow' and 'hipercow.dide' versions agree (1.1.3)
#> ✔ Submitted task 'f9e8fa83205e66ef9cd8bd7f3ff1e549' using 'dide-windows'
#>
#> ── hipercow 1.0.55 running at 'V:/cluster/hipercow-vignette/hv-20250423-7d83f687
#> ℹ library paths:
#> •
#> V:/cluster/hipercow-vignette/hv-20250423-7d83f6872b6bb/hipercow/lib/windows/4.4.2
#> • I:/bootstrap-windows/4.4.2
#> • C:/Program Files/R/R-4.4.2/library
#> ℹ id: f9e8fa83205e66ef9cd8bd7f3ff1e549
#> ℹ starting at: 2025-04-23 10:57:58.901961
#> ℹ Task type: expression
#> • Expression: { [...]
#> • Locals: moo
#> • Environment: default
#> R_GC_MEM_GROW: 3
#> CMDSTAN: I:/cmdstan/cmdstan-2.35.0
#> CMDSTANR_USE_RTOOLS: TRUE
#> ───────────────────────────────────────────────────────────────── task logs ↓ ──
#> -----
#> Moooooo!
#> ------
#> \ ^__^
#> \ (oo)\ ________
#> (__)\ )\ /\
#> ||------w|
#> || ||
#>
#> ───────────────────────────────────────────────────────────────── task logs ↑ ──
#> ✔ status: success
#> ℹ finishing at: 2025-04-23 10:57:58.901961 (elapsed: 0.5092 secs)
#> ✔ Successfully ran test task 'f9e8fa83205e66ef9cd8bd7f3ff1e549'See the overall configuration (we will often ask for this):
hipercow_configuration()
#>
#> ── hipercow root at /home/rfitzjoh/net/home/cluster/hipercow-vignette/hv-20250423-7d83f6872b6bb ─────────
#> ✔ Working directory '.' within root
#> ℹ R version 4.4.2 on Linux (rfitzjoh@wpia-dide300)
#>
#> ── Packages ──
#>
#> ℹ This is hipercow 1.1.3
#> ℹ Installed: hipercow.dide (1.1.3), conan2 (1.9.101), logwatch (0.1.1), rrq (0.7.22)
#>
#> ── Environments ──
#>
#> ── default
#> • packages: (none)
#> • sources: (none)
#> • globals: (none)
#>
#> ── empty
#> • packages: (none)
#> • sources: (none)
#> • globals: (none)
#>
#> ── Drivers ──
#>
#> ✔ 1 driver configured ('dide-windows')
#>
#> ── dide-windows
#> • cluster: wpia-hn
#> • shares: 1 configured:
#> → (local) /home/rfitzjoh/net/home => \\qdrive.dide.ic.ac.uk\homes\rfitzjoh => V: (remote)
#> • r_version: 4.4.2
#> • path_lib: hipercow/lib/windows/4.4.2
#> • platform: windows
#> • username: rfitzjohThe DIDE Cluster
We have one MS-HPC (think Azure) cluster called wpia-hn
hosted in South Kensington, built mainly with recent 32-core, 512Gb
nodes, and some older but still capable nodes. Most of these are running
Windows, but MS-HPC can also attach Linux nodes, which we have now begun
supporting. Please let us now how you get on.
Default environment variables
#> name value
#> 1 CMDSTAN I:/cmdstan/cmdstan-2.35.0
#> 2 CMDSTANR_USE_RTOOLS TRUEThe Nodes
In the hipercow root we just made, we can have a look at
what the cluster is like with hipercow_cluster_info(). This
gives us information we can then use with
hipercow_resources to request particular resources. See
vignette("parallel") for more information.
hipercow_cluster_info()
#> $resources
#> $resources$name
#> [1] "wpia-hn"
#>
#> $resources$node_os
#> [1] "windows"
#>
#> $resources$max_cores
#> [1] 32
#>
#> $resources$max_ram
#> [1] 512
#>
#> $resources$queues
#> [1] "AllNodes" "Testing"
#>
#> $resources$default_queue
#> [1] "AllNodes"
#>
#> $resources$build_queue
#> [1] "BuildQueue"
#>
#> $resources$testing_queue
#> [1] "Testing"
#>
#> $resources$redis_url
#> [1] "wpia-hn.hpc.dide.ic.ac.uk"
#>
#> $resources$nodes
#> [1] "wpia-001" "wpia-002" "wpia-003" "wpia-004" "wpia-005" "wpia-006"
#> [7] "wpia-007" "wpia-008" "wpia-009" "wpia-010" "wpia-011" "wpia-012"
#> [13] "wpia-013" "wpia-014" "wpia-015" "wpia-016" "wpia-017" "wpia-018"
#> [19] "wpia-019" "wpia-020" "wpia-021" "wpia-022" "wpia-023" "wpia-024"
#> [25] "wpia-025" "wpia-026" "wpia-027" "wpia-028" "wpia-029" "wpia-030"
#> [31] "wpia-031" "wpia-032" "wpia-033" "wpia-034" "wpia-035" "wpia-036"
#> [37] "wpia-037" "wpia-038" "wpia-039" "wpia-040" "wpia-043" "wpia-044"
#> [43] "wpia-045" "wpia-046" "wpia-047" "wpia-048" "wpia-051" "wpia-052"
#> [49] "wpia-053" "wpia-054" "wpia-055" "wpia-056" "wpia-057" "wpia-058"
#> [55] "wpia-059" "wpia-060" "wpia-061" "wpia-062" "wpia-063" "wpia-064"
#> [61] "wpia-065" "wpia-066" "wpia-067" "wpia-068" "wpia-069" "wpia-070"
#> [67] "wpia-071" "wpia-072" "wpia-073" "wpia-074" "wpia-075" "wpia-076"
#> [73] "wpia-077" "wpia-078" "wpia-079" "wpia-080" "wpia-081" "wpia-082"
#>
#>
#> $r_versions
#> [1] '4.2.3' '4.3.0' '4.3.2' '4.3.3' '4.4.0' '4.4.1' '4.4.2' '4.4.3'
#>
#> $redis_url
#> [1] "wpia-hn.hpc.dide.ic.ac.uk"Nodes: At present we have around 70 nodes, numbered
wpia-xxx- there are gaps because some nodes are experimental, or serving other purposes not on the cluster at the moment.Cores: at present, the largest node on this cluster has 32 cores - in fact all of the nodes do. This will change as we grow the cluster, but for now, all the nodes are similar. The 32-core nodes are our favourite compromise at the moment between power usage, computational speed, and density, because physical space is limited.
Memory: most of the nodes have 512Gb of RAM; only nodes 059-070 are slightly smaller with 384Gb. This will change; some larger nodes may arrive, and we may try and beef up some older nodes to ensure you have enough RAM per job.
Queues: for Windows nodes, the unfortunate legacy
AllNodesqueue is used; for LinuxLinuxNodes. There is an additional node currently reserved forTrainingand development, and if you come to ahipercowworkshop, you will likely submit small jobs to this one. Each driver (Windows or Linux) has a default queue set, so your jobs should run on appropriate nodes without you doing anything. We may add different queues to subset our nodes into different capabilities, in which case more may appear.R versions: you can see a few R versions that are supported on all cluster nodes, including the most recent, and a couple of older versions. We generally try to support the current and previous versions of R. It’s a good idea to keep up-to-date.
The redis URL is not something you need to do anything with for the moment.
Cluster Storage
The headnode, wpia-hn.hpc.dide.ic.ac.uk has storage
which is connected to all the cluster nodes via a fast InfiniBand
network. When the cluster nodes talk to that share, they will use the
infiniband without you having to do anything special.
The storage can also be mapped (or mounted) so you can see the same files from your desktop or laptop, just at a standard network speed. You’ll need access to some share on that drive - talk to your PI about that - and then follow the instructions earlier in this vignette for how to map it.
The important thing is that you should definitely use this storage if possible for any cluster tasks doing a significant amount of file reading or writing, and it’s highly recommended to use it for all work using this cluster.
Also, if you refer to data on the cluster storage from within your task, this is the one area where you’ll have to do something different if you are targeting Windows cluster nodes, compared to Linux cluster nodes. We’ve already talked about mapping, mounting, or referring to DIDE shares from your local computer. Here we need to talk about referring to them within a cluster job, which might be running on Windows, or Linux.
Cluster Storage on Windows Compute nodes
You can refer to DIDE network shares using fully-qualified network paths, so if I have a file in my home directory I want to read in R on a Windows node, I can write:-
x <- readLines("//qdrive.dide.ic.ac.uk/homes/wes/hello.txt")which is the same as I would write on a local Windows computer. This will work for small tasks, but as we’ve said, you should not use this for any large volumes of I/O. Instead you should you a share on the cluster-storage.
Furthermore, if you are referring to the cluster-storage within a
cluster job, you should refer to wpia-hn as
wpia-hn-app to ensure you use the fast Infiniband network
connection to get your data. For example, if I have some data that I
refer to from my Windows local computer as
//wpia-hn.hpc.dide.ic.ac.uk/flu-project/data.dat, then to
access the same data from a cluster job, I should write
//wpia-hn-app/flu-project/data.dat.
Cluster Storage on Linux Compute nodes
We cannot access network paths directly; they need to be explicitly mounted, but that is hard to do reliably from within a cluster job. We have therefore mounted the main cluster shares on all cluster nodes in advance, and you will have the same read/write access as you would from any other machine. But you will need to refer to the network shares in the right way. Specifically:-
To refer to a file on a home directory (for example,
//qdrive.dide.ic.ac.uk/homes/wes/hello.txt) from within a cluster job on a Linux node, you should write/didehomes/wes/hello.txt- noting yet again: we do not recommend using home directories for any significant data tasks.To refer to data on a cluster share (for example,
//wpia-hn.hpc.dide.ic.ac.uk/flu-project/data.dat) from your Linux cluster job, you should write/wpia-hn/flu-project/data.dat. This is already wired up to use the fast network connection.
If you cannot find the data you are expecting, get in touch with Wes; data has been moved around partly to prepare for Linux, and partly because of our departmental relocation, so some data appearing dormant has not yet been migrated.