Full EpiEstim vignette
Rebecca Nash
2026-07-20
Source:vignettes/full_EpiEstim_vignette.Rmd
full_EpiEstim_vignette.RmdThe EpiEstim package allows you to estimate the time
varying reproduction number (Rt) from epidemic data. This
vignette will take you through the key stages in the process of
estimating Rt and also introduce some additional packages
(incidence and projections) that can work
alongside EpiEstim in a typical outbreak analysis workflow. Please also
see the ‘Examples’ and ‘FAQs’ sections.
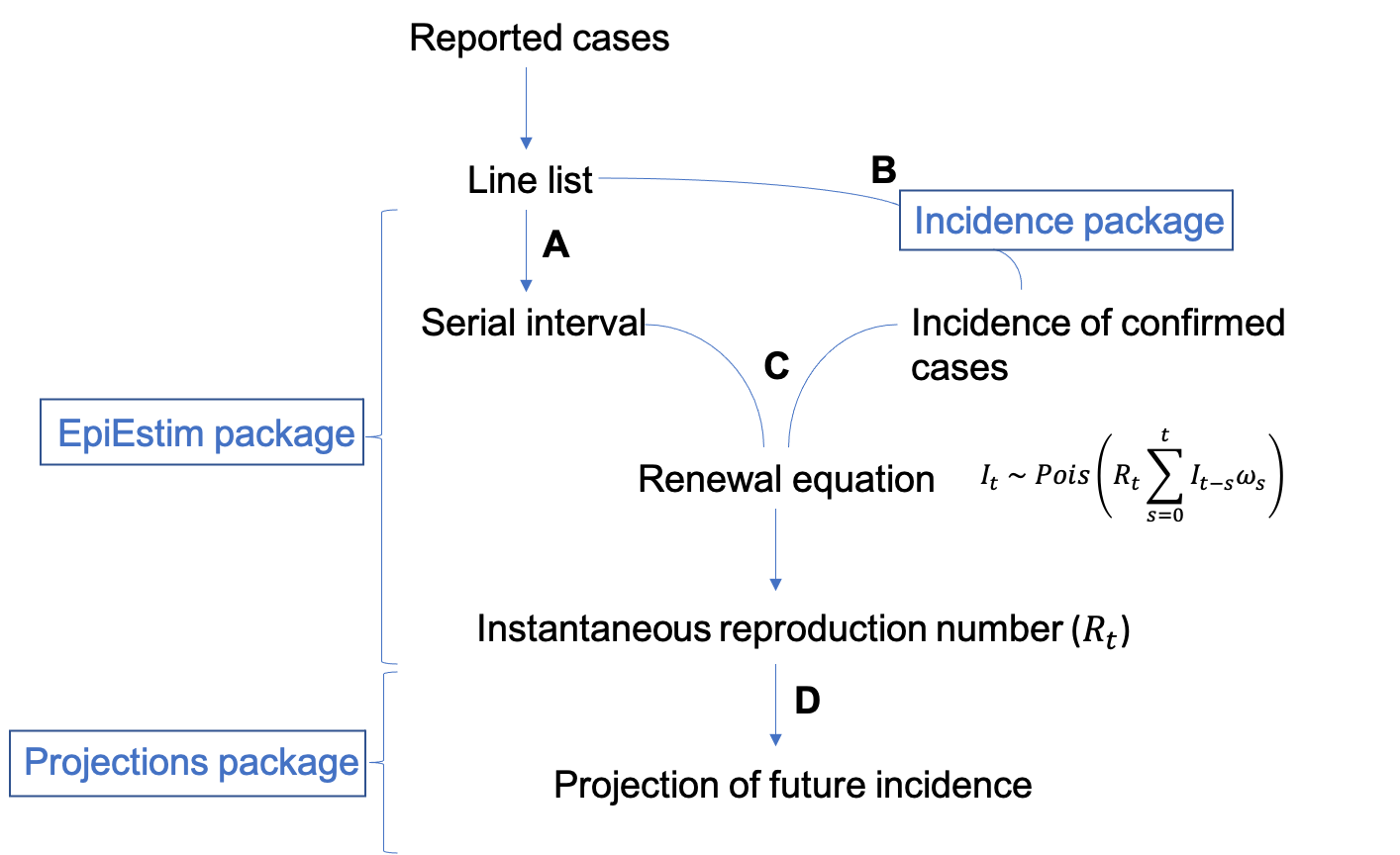
Input data
The standard way that outbreak data is presented is in the form of a linelist, which incorporates detailed information on the reported cases of an outbreak. For example:
| Case ID | Date Reported | Date Symptom Onset | Date Exposure | M/F | Age | Outcome | Classification |
|---|---|---|---|---|---|---|---|
| 1 | dd/mm/yy | dd/mm/yy | dd/mm/yy | F | 26 | recovered | confirmed |
| 2 | dd/mm/yy | dd/mm/yy | dd/mm/yy | M | 32 | died | suspected |
| 3 | dd/mm/yy | dd/mm/yy | dd/mm/yy | M | 41 | recovered | confirmed |
| 4 | dd/mm/yy | dd/mm/yy | dd/mm/yy | F | 68 | recovered | probable |
| … | … | … | … | … | … | … | … |
In order to estimate Rt, EpiEstim needs to be supplied with an estimate of the serial interval distribution (step A) and the incidence of confirmed cases (step B).
Step A: Serial Interval
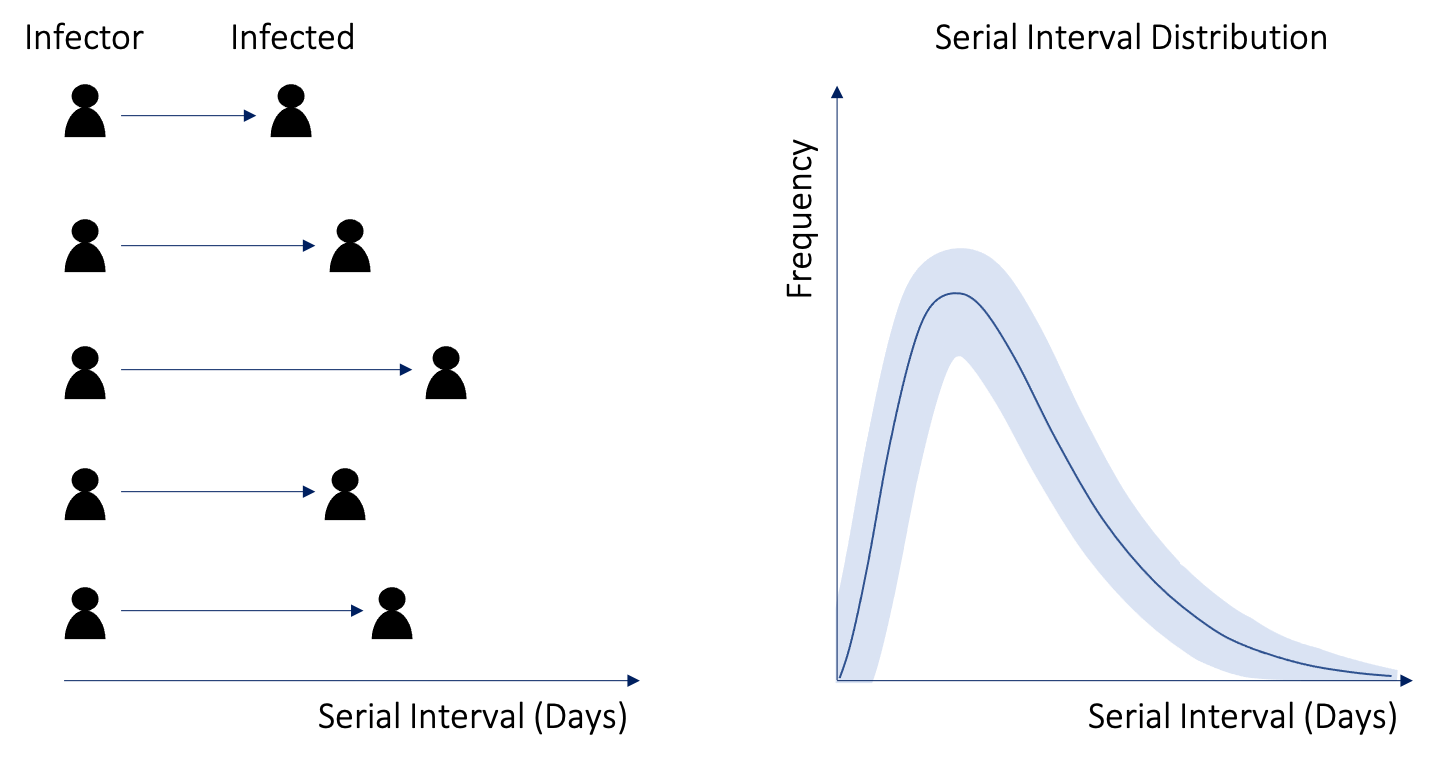
The serial interval is the time between symptom onset in successive cases. The serial interval distribution can be parameterised either by estimates taken from the literature or it can be estimated directly from the linelist if you have data for infector-infected pairs.
Serial interval from the literature:
If a disease has been well characterised, then you have the option to use estimates of the serial interval that can be found in the literature. Note that EpiEstim assumes the serial interval is strictly positive. You can either supply the mean and standard deviation (parametric distribution) of the serial interval, or its full distribution (non-parametric distribution). See examples A and B in the Examples section.
Serial interval from infector-infected pairs:
This feature was incorporated into EpiEstim by Thompson et al 2019. If you have data for infector-infected pairs of cases you can estimate the serial interval distribution directly from your own data and account for its uncertainty.
For example, if “Case ID” represents the person who has been exposed and infected and “Infector ID” represents the potential source of infection, then you can format the contact data as follows:
| Case ID | Infector ID | Source of Exposure |
|---|---|---|
| 299 | 208 | funeral |
| 302 | 272 | hospital |
| 341 | 301 | household |
| 389 | 312 | other |
| … | … | … |
Combined with dates of symptom onset in the line list, these can be used to estimate the serial interval distribution in this outbreak.
In an ideal world we would have access to data in the format above, where dates of symptom onset for infector/infected individuals are very well defined, but often we do not know the exact date of symptom onset. In this situation, EpiEstim allows you to account for this uncertainty using “interval-censored data”, where there are lower and upper bounds for the symptom onset time in infector/infected cases (Thompson et al 2019).
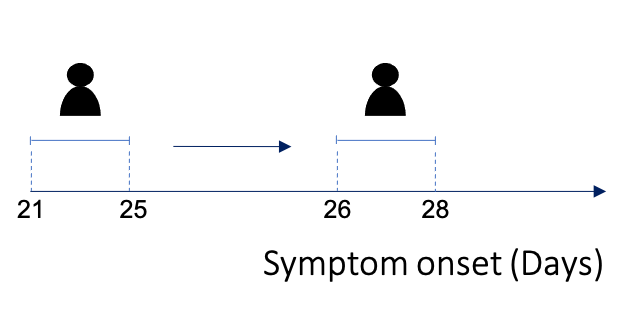
This type of data may look like this:
| Day infector symptom onset (LB) | Day infector symptom onset (UB) | Day infected symptom onset (LB) | Day infected symptom onset (UB) |
|---|---|---|---|
| 21 | 25 | 26 | 28 |
| 23 | 26 | 26 | 30 |
| 34 | 39 | 41 | 43 |
| 46 | 52 | 54 | 55 |
| … | … | … | … |
For an example of how we can parameterise the SI using this method, see example C in the Examples section.
It is important to note that, particularly for outbreaks of emerging diseases, the serial interval estimate can be updated when you gather more data as the epidemic progresses.
Step B: Incidence
The package incidence can be used to easily plot
incidence, as shown in the following example using a pre-loaded
EpiEstim dataset of an Influenza outbreak in 2009
(“Flu2009”).
data("Flu2009") # load example dataset
head(Flu2009$incidence) # displays the first n rows of the Flu2009$incidence data
#> dates I
#> 1 2009-04-27 1
#> 2 2009-04-28 1
#> 3 2009-04-29 0
#> 4 2009-04-30 2
#> 5 2009-05-01 5
#> 6 2009-05-02 3For instance, in this example, incidence (I) is a count of
individuals with a symptom onset on a particular date. We can plot this
using incidence as follows:
plot(as.incidence(Flu2009$incidence$I, dates = Flu2009$incidence$dates))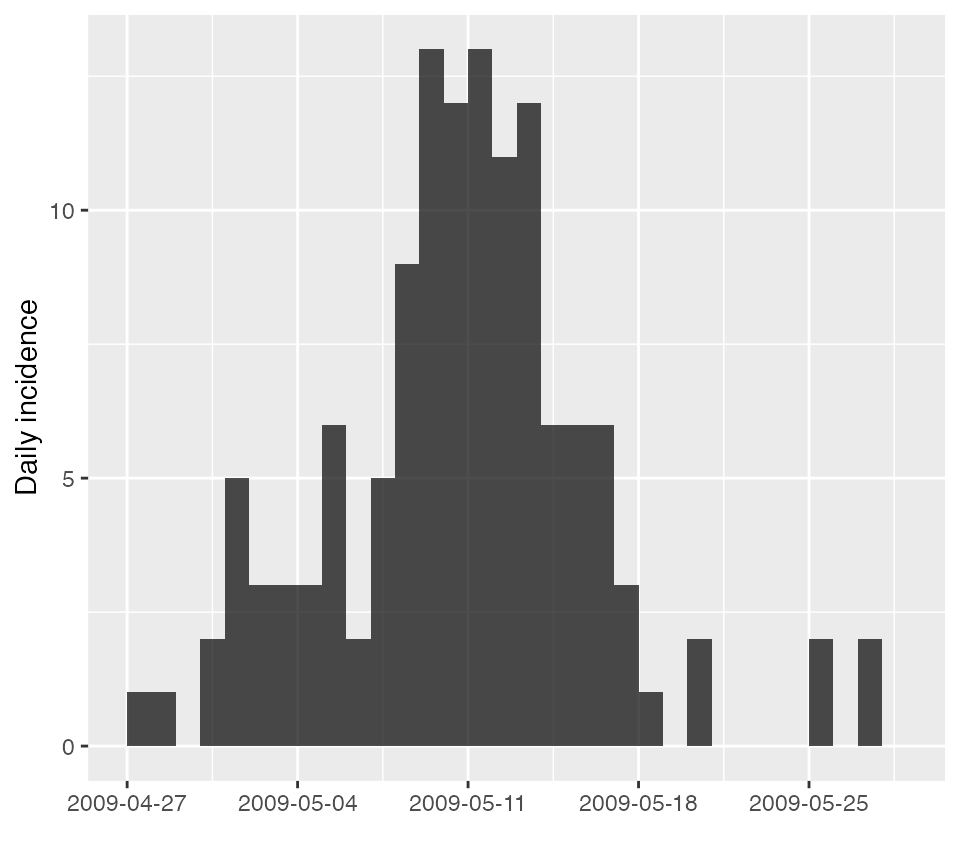
incidence can convert the dates of symptom onset from
linelists with various formats into an incidence object that can be
easily understood by EpiEstim.
Please see the incidence vignette overview for more
details, features and examples: https://cran.r-project.org/web/packages/incidence/vignettes/overview.html
Local and Imported cases:
If you have data that distinguishes between local and imported cases, this can be supplied to EpiEstim with local and imported incidence in two separate columns, for example in this dataset:
| Date | Incidence Overall | Incidence Local | Incidence Imported |
|---|---|---|---|
| dd/mm/yy | 31 | 28 | 3 |
| dd/mm/yy | 48 | 46 | 2 |
| dd/mm/yy | 45 | 44 | 1 |
| dd/mm/yy | 52 | 48 | 4 |
| … | … | … | … |
Temporally aggregated incidence data:
This vignette provides examples using incidence data that is
available on a daily basis. If you have incidence data that is reported
over aggregated timescales, such as weekly data or incidence reported 3
times a week, you will need to provide an additional parameter ‘dt’ to
the estimate_R() function introduced in step C.
For full details about using EpiEstim for temporally aggregated incidence data, see the “EpiEstim_aggregated_incidence” vignette.
Estimate Rt
Once you have an incidence object (based on the dates of symptom onset) and information on the serial interval distribution, we can use the renewal equation (a form of branching process model) to estimate Rt. Rt is the average number of secondary cases that an infected individual would infect if the conditions remained as they were at time t (Cori et al 2013).
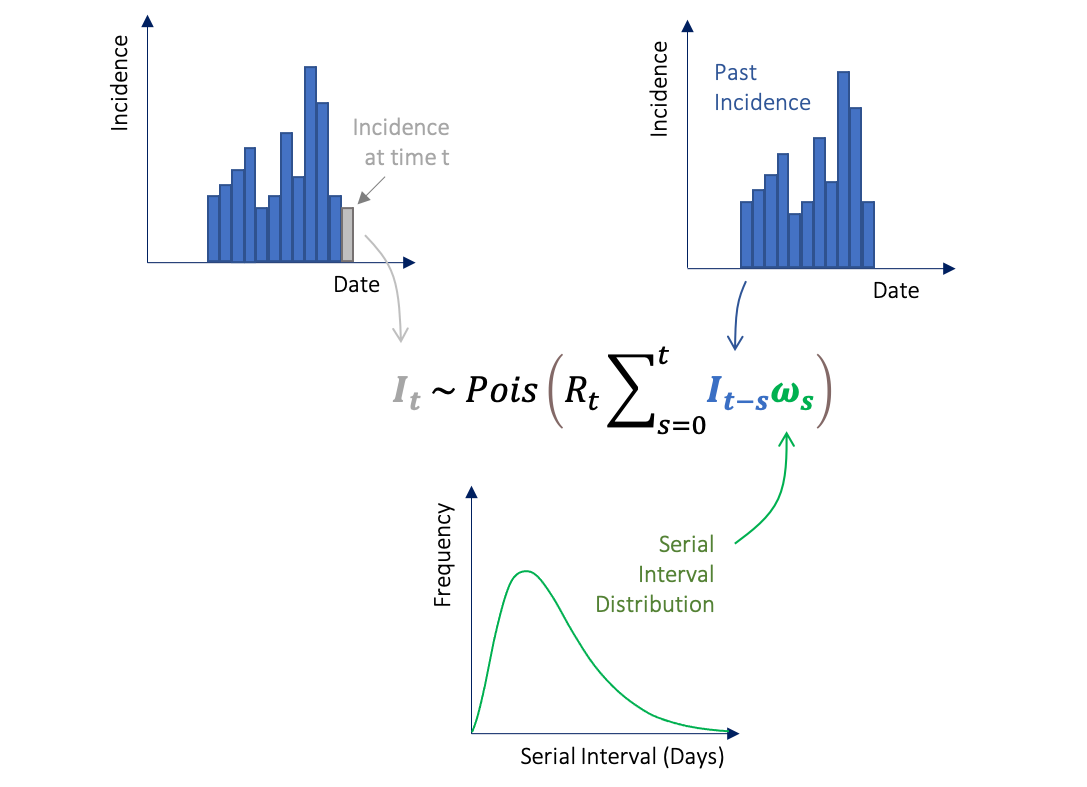
Here It represents the incidence of symptom onset at time t, which is approximated by a Poisson process using the renewal equation. Rt is what we want to estimate, It-s is the past incidence and is the serial interval distribution.
Step C: estimate_R()
This is where the estimate_R() function comes in. We
supply EpiEstim with the incidence and tell the package
which method we want to use to parameterise the serial interval.
estimate_R(
incid = incidence_object,
method = c("parametric_si", "non_parametric_si", "si_from_data",
"uncertain_si", "si_from_sample"), # choose one e.g. method = "parametric_si"
si_data = NULL, # if using "si_from_data" supply infector-infected data here
si_sample = NULL, # if using "si_from_sample" supply matrix where each column is an SI to be explored
config = make_config(list())
)As mentioned, the serial interval (SI) can be defined using one of the following methods:
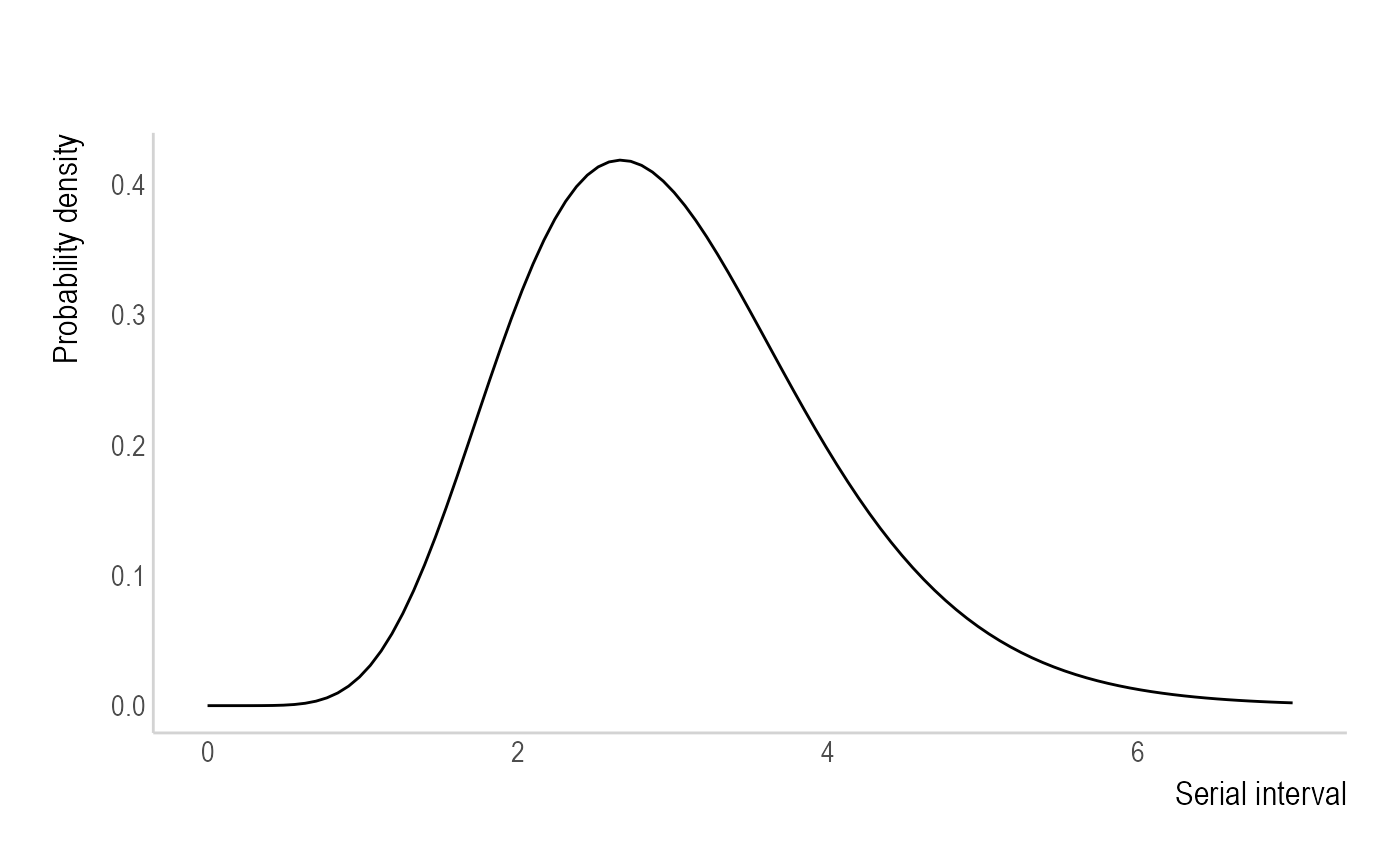
Parametric - "parametric_si" uses the
mean and standard deviation. Ex. The user can supply
mean_si = 3 and std_si = 1, which generates an
offset gamma distribution as the default:
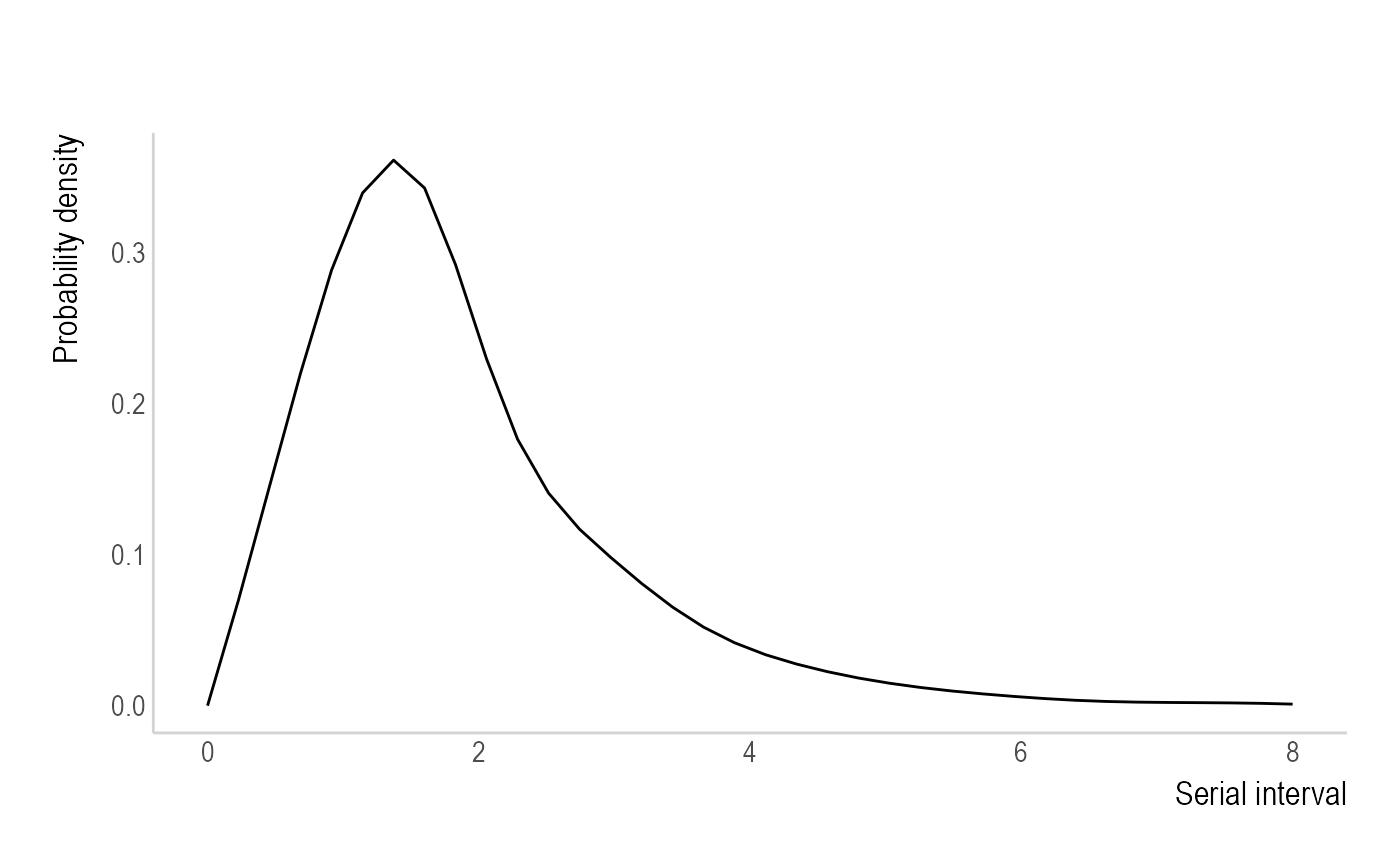
Non-parametric - "non_parametric_si"
uses the discrete distribution of the SI. Ex. The user can supply
si_distr = c(0.000, 0.233, 0.359, 0.198, 0.103, 0.053, 0.027, 0.014, 0.007, 0.003, 0.002, 0.001),
which generates:
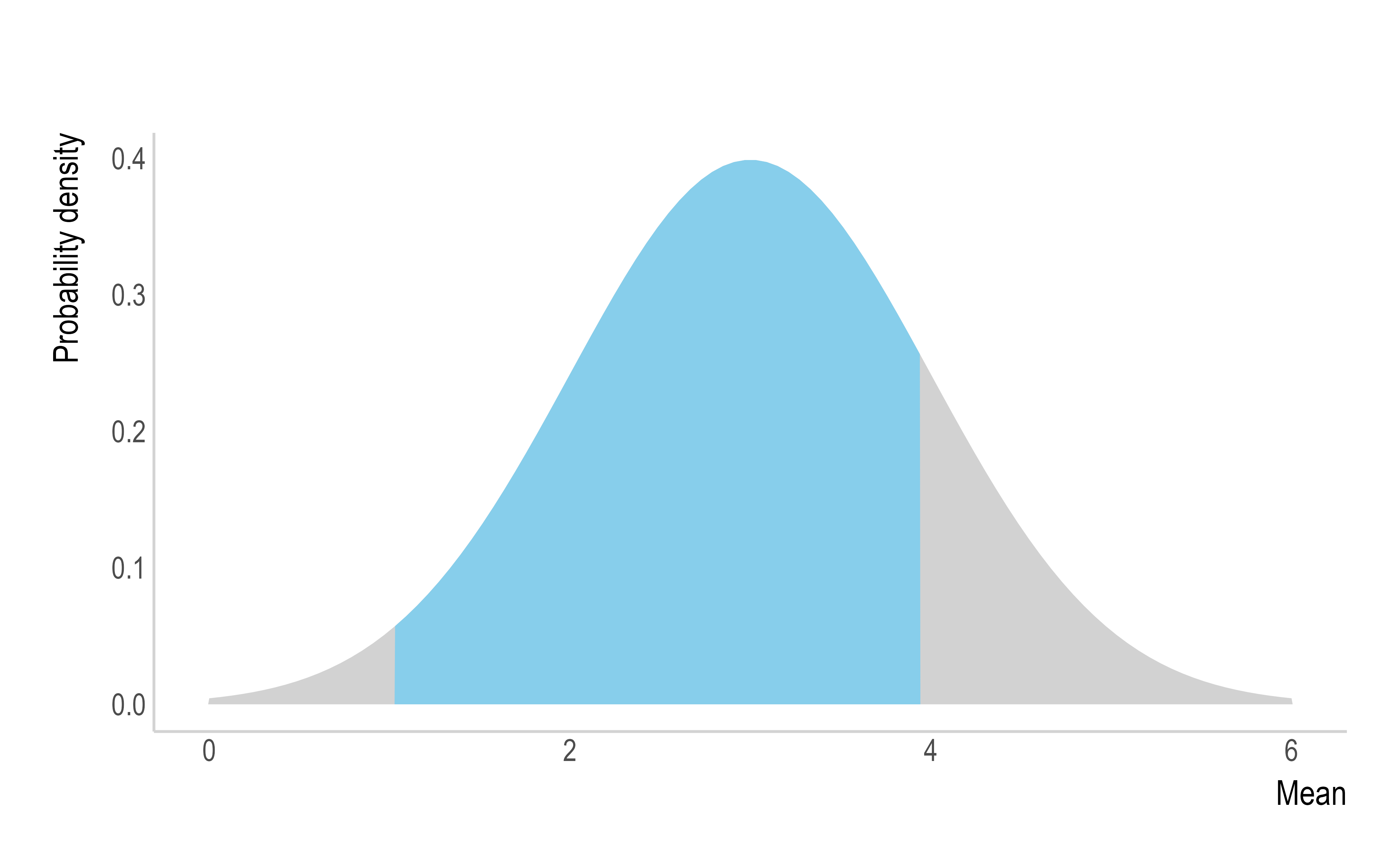
Uncertain - If we are particularly uncertain about
the parameters of the SI distribution, then we can use
"uncertain_si" to draw the mean and standard deviation from
truncated normal distributions and generate multiple potential SI
distributions and integrate the results.
Ex. Here, the mean of the SI will be drawn from a normal distribution with a mean of 3 and SD of 1, truncated at 1 and 4 (left). The SD of the SI will be drawn from a normal distribution with a mean of 1.5 and SD of 0.5, truncated at 0.5 and 2.5 (centre). The drawn values will parameterise multiple SI distributions to be considered, but for clarity, the example below only displays 5 (right).
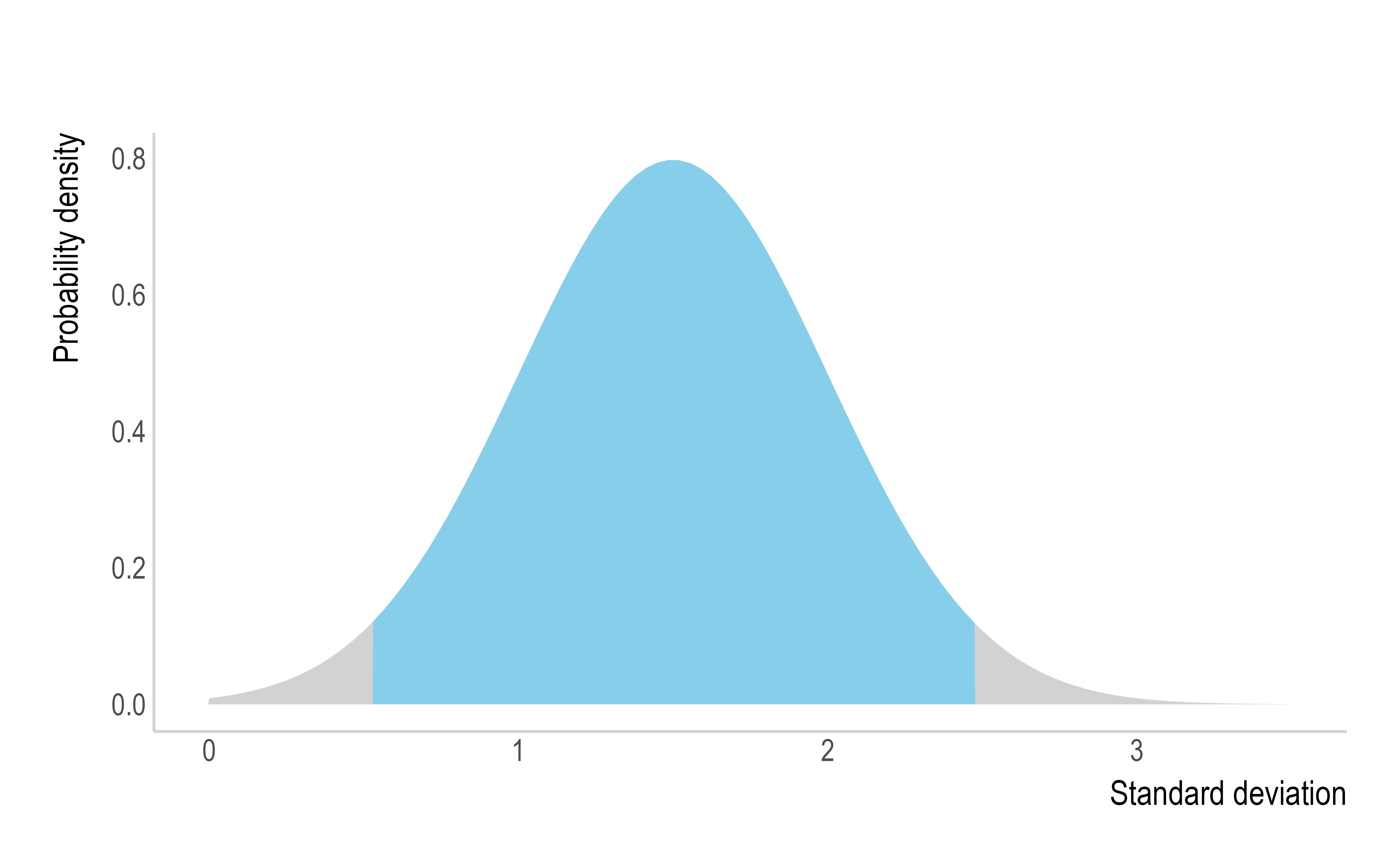
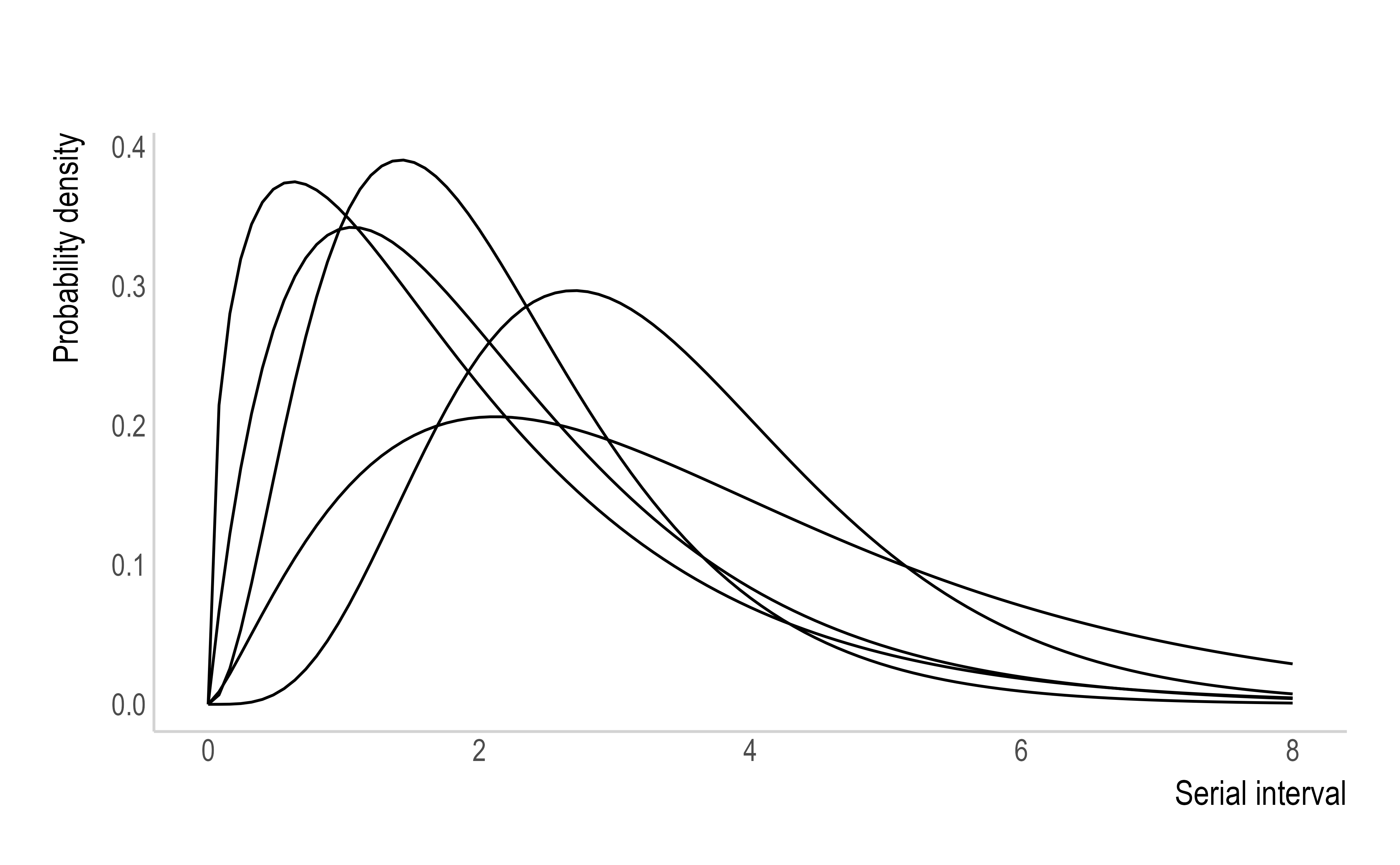
This would be written within the config argument in
estimate_R() as:
estimate_R(incid = incid,
method = "uncertain_si",
config = make_config(list(
mean_si = 3, std_mean_si = 1, # Mean distribution is N(3,1)
min_mean_si = 1, max_mean_si = 4, # Truncated at 1 and 4
std_si = 1.5, std_std_si = 0.5, # SD distribution is N(1.5,0.5)
min_std_si = 0.5, max_std_si = 2.5, # Truncated at 0.5 and 2.5
n1 = 5, # 5 pairs of values for the mean and SD will be drawn
n2 = 50))) # Size of posterior sample of Rt drawn for each pairPlease note that n1 = 5 is very low and chosen purely
for illustrative purposes. The default values for n1 and n2 are
n1 = 500 and n2 = 50, which can be modified
based on the users preference. If the default values are used, a sample
of size 25,000 (n1 x n2) of the joint
posterior distribution of Rt will be obtained over each time
window. Bear in mind that the larger these values, the longer the
estimate_R() function will take to run.
From data - "si_from_data" allows you
to estimate the SI by Markov chain Monte Carlo (MCMC) from
infector-infected data. The user has the choice of which parametric
distribution the SI will take, either: Gamma "G", Weibull
"W", Lognormal "L", or shifted by 1: Gamma
"off1G", Weibull "off1W", Lognormal
"off1L"
mcmc_control is where you define the properties of the
MCMC, i.e. the burn-in and the thinning of MCMC chains. Burn-in is the
number of iterations to be discarded as “warm-up”, for instance, if
burnin = 1000 the output is only recorded after
1000 iterations have run. Thinning determines how much the MCMC chains
should be thinned out, if thin = 10 then 1 in every 10
iterations will be kept. The seed, e.g. seed = 1, acts as
the starting point for the random number generator of the MCMC
estimation. Setting the seed allows you to obtain reproducible results
as you will get the same result each time you run the same process.
mcmc_control <- make_mcmc_control(burnin = burnin, # number of iterations to be discarded as burn-in
thin = thin, # defining how much the MCMC chains should be thinned
seed = mcmc_seed) # set the seed for reproducibilityThis then feeds into the config argument of
estimate_R():
estimate_R(incid = incid,
method = "si_from_data",
si_data = data$si_data, # supply dataframe with symptom onset data
config = make_config(si_parametric_distr = "G", # choose distribution
mcmc_control = mcmc_control,
seed = overall_seed, # set seed for reproducibility
n1 = 500, # number of posterior samples drawn for dist. of the SI
n2 = 50)) # number of posterior samples drawn for dist. of Rt for each
# SI consideredThe variables in data$si_data should take the names:
- EL - Exposure Left (lower bound for the infector)
- ER - Exposure Right (upper bound for the infector)
- SL - Secondary Left (lower bound for the infected individual)
- SR - Secondary Right (upper bound for the infected individual)
As described above in ‘Step A: Serial Interval’, you may know the exact day of symptom onset for the infector-infected pairs.
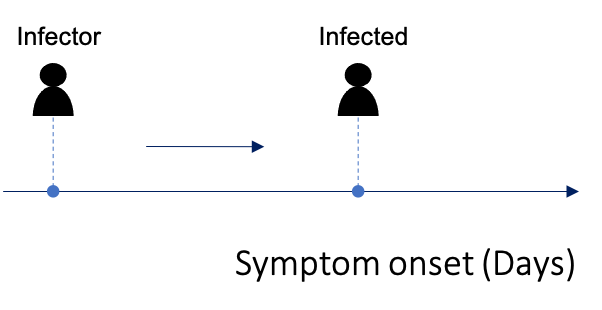
This can be supplied as data$si_data where EL and ER are
both given the symptom onset day for the infector, whilst SL and SR are
both given the symptom onset day for the infected individual:
#> EL ER SL SR
#> 1 21 21 26 26
#> 2 23 23 26 26
#> 3 34 34 41 41
#> 4 46 46 54 54
#> 5 ... ... ... ...Or instead you may have data that gives you a range of potential symptom onset dates.
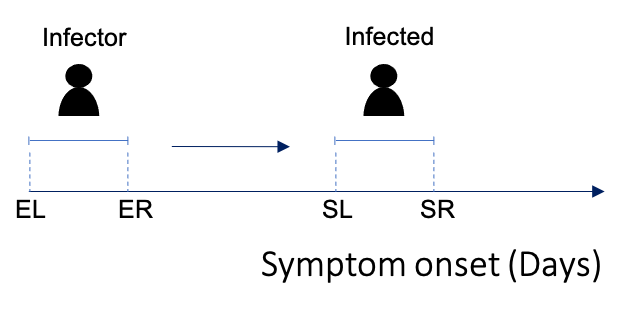
In which case, each column in data$si_data corresponds
to the lower and upper bounds for symptom onset in each pair.
#> EL ER SL SR
#> 1 21 25 26 28
#> 2 23 26 26 30
#> 3 34 39 41 43
#> 4 46 52 54 55
#> 5 ... ... ... ...From sample - ("si_from_sample") allows
you to input the posterior sample from a previously estimated SI
distribution. This means that you don’t have to re-estimate the SI every
time you run estimate_R() if you don’t want to, and you can
also estimate the SI elsewhere and put that into EpiEstim. Ex. The user
would need to supply si_sample with a matrix where each
column corresponds to one SI distribution to be explored. This would
look something like this:
head(si_sample[,1:6])
#> 1 11 21 31 41 51
#> [1,] 0.00000000 0.00000000 0.00000000 0.00000000 0.00000000 0.00000000
#> [2,] 0.50864213 0.53282683 0.39873373 0.43800937 0.47079171 0.46166619
#> [3,] 0.23223637 0.27630179 0.27242109 0.25093584 0.23715407 0.23921707
#> [4,] 0.11859018 0.11730828 0.15667303 0.14000878 0.12810521 0.13074405
#> [5,] 0.06311048 0.04613796 0.08431215 0.07734176 0.07102036 0.07289353
#> [6,] 0.03433206 0.01741882 0.04378072 0.04249667 0.03992217 0.04107379and would be written in estimate_R() as:
estimate_R(incid = incid,
method = "si_from_sample",
si_sample = si_sample, # matrix of SI distributions
config = make_config(list(n2 = 50)))See examples A-E in the Examples section to demonstrate
estimate_R() with data for each of these methods.
Overlapping time windows
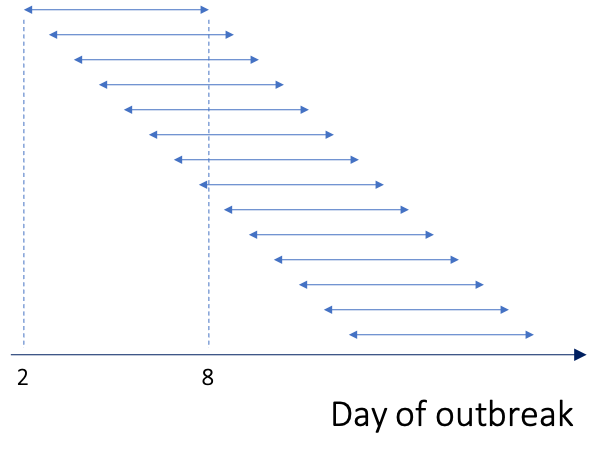
By default Rt is estimated over weekly sliding windows,
i.e. successive overlapping 7 day time windows as shown above. If you
wish to specify a different time window over which Rt is
estimated, you use the t_start = and t_end =
arguments within config = of the estimate_R()
function. t_start is the starting time for the window of
Rt estimation and t_end is the end time of the
window. As EpiEstim relies on past incidence to generate estimates of
Rt, the earliest a time window can start is on day 2 of the
epidemic. For example, if you wanted to estimate Rt over
biweekly sliding windows you could do so as follows:
data(Flu2009)
# Each row of Flu2009$incidence corresponds to one day in the outbreak. t_start`
# is a sequence of start days for the sliding window, starting on day 2 ending
# 2 weeks before the last day in the dataset:
t_start <- seq(2, nrow(Flu2009$incidence) - 13)
# `t_end` is a sequence of end dates for the window 2 weeks after each start
# date defined above:
t_end <- t_start + 13
# Estimate R over biweekly sliding windows by changing `t_start` and `t_end`
# within config in estimate_R:
res <- estimate_R(incid = Flu2009$incidence,
method = "non_parametric_si",
config = make_config(list(
si_distr = Flu2009$si_distr,
t_start = t_start,
t_end = t_end)))
head(res$R[1:6])
#> t_start t_end date_start date_end Mean(R) Std(R)
#> 1 2 15 2009-04-28 2009-05-11 1.627509 0.1842791
#> 2 3 16 2009-04-29 2009-05-12 1.492158 0.1590645
#> 3 4 17 2009-04-30 2009-05-13 1.428000 0.1428000
#> 4 5 18 2009-05-01 2009-05-14 1.282858 0.1257946
#> 5 6 19 2009-05-02 2009-05-15 1.157739 0.1129838
#> 6 7 20 2009-05-03 2009-05-16 1.113414 0.1071383
# Each row now corresponds to a biweekly window. If you take the first row here
# you can see that R has been estimated over 14 days where all cases with onset
# from day 2 to day 15 of the outbreak are included.Rt is then plotted for each time window on the last day of that window. So in the example above, the estimate of Rt for the window from day 2 to day 15 will be plotted on day 15 (11th May). This means that it appears as if you’re starting your estimation later than you are because the plot for Rt does not start until the end of the first window.
plot(res, legend = FALSE, "R") # specifying "R", "SI" or "incid" allows you to plot just the single panel
#> Warning: The `size` argument of `element_line()` is deprecated as of ggplot2 3.4.0.
#> ℹ Please use the `linewidth` argument instead.
#> ℹ The deprecated feature was likely used in the EpiEstim package.
#> Please report the issue at <https://github.com/mrc-ide/EpiEstim/issues>.
#> This warning is displayed once per session.
#> Call `lifecycle::last_lifecycle_warnings()` to see where this warning was
#> generated.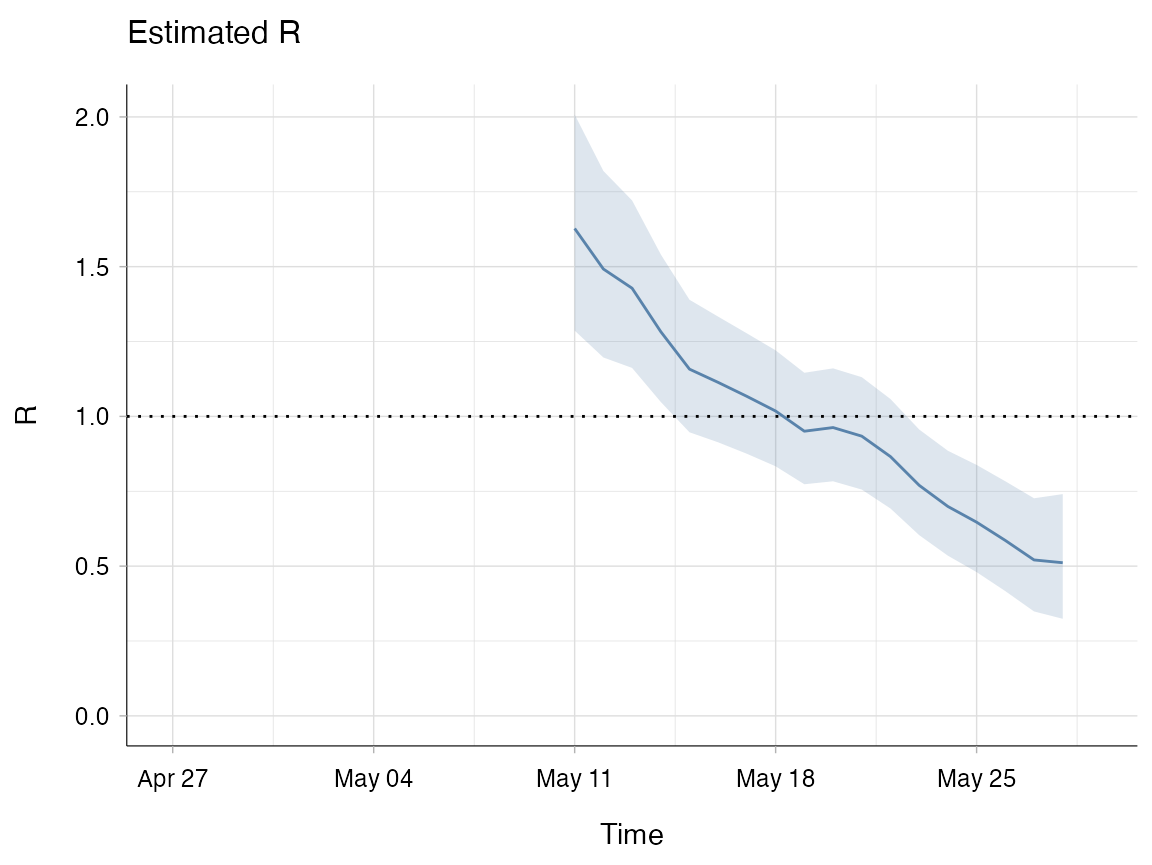
When choosing the length of the time window, there is essentially a trade-off. A longer window may give you less uncertainty in your estimate, but could disguise important temporal changes, whereas a shorter window may be more influenced by random noise in the data. A good starting point might be to choose a window length that is at least the mean of the SI distribution. A longer time window is more appropriate if you believe the epidemiological situation has not changed (e.g. no new interventions have been implemented).
Non-overlapping time windows
You may want to compare Rt before and after an intervention has been implemented. In this instance, you won’t necessarily need smooth overlapping time windows. For example, imagine that you implemented an intervention on the 11th May. You could compare the average estimate for Rt before the intervention was implemented and then after.
data(Flu2009)
# set t_start for day 2 of the outbreak and day 15 of the outbreak (11th May):
t_start <- c(2, 15)
# set t_end to day 14 and the last day in the dataset:
t_end <- c(14, nrow(Flu2009$incidence))
# Estimate R over two periods of time (before and after intervention) by changing
# `t_start` and `t_end` within config in estimate_R:
res2 <- estimate_R(incid = Flu2009$incidence,
method = "non_parametric_si",
config = make_config(list(
si_distr = Flu2009$si_distr,
t_start = t_start,
t_end = t_end)))
plot(res2, legend = FALSE, "R")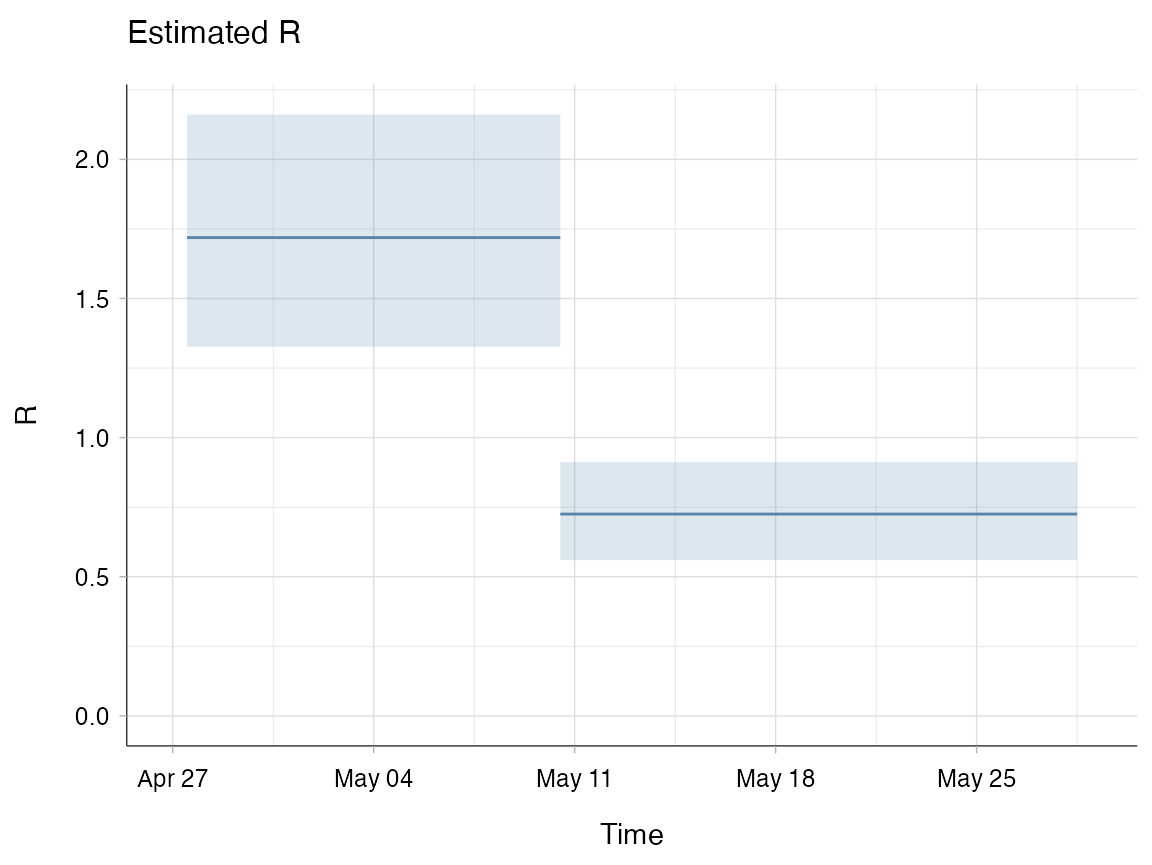
Note that if using incidence by date of symptom onset and depending on the disease you may need to have a buffer that accounts for the incubation period (average time between infection and symptom onset) of the disease. In other words, you need to factor in the people who were infected before the intervention was implemented, but became symptomatic after the intervention was implemented. Additionally, you need to consider whether the type of intervention implemented would have an immediate effect or whether it’s likely to result in a more gradual change.
Prior for Rt
The gamma distributed prior for the mean and standard deviation of
Rt can be set using the mean_prior= and
std_prior= arguments within config= of the
estimate_R() function. If you do not define any values for
these arguments then the default values are used, which are a mean of 5
and standard deviation of 5. The default has been set for an unknown
pathogen with relatively high R and high uncertainty. With this prior,
if we estimate R to be below 1, then we can be more confident that the
result is strongly data-driven.
For example, if you do not want to use the default prior, you can set a mean of 2 and standard deviation of 1:
estimate_R(incid = data$incid,
method = "non_parametric_si",
config = make_config(list(
si_distr = data$si_distr,
mean_prior = 2,
std_prior = 1)))Forecast future incidence
Estimates for Rt can then feed into packages designed to project or
simulate what the future incidence could be based on our estimates.
There are various packages available, but here we will use the
projections package by Nouvellet et al 2018.
Step D: Projections package
The projections package uses the daily incidence, serial interval and Rt estimate to simulate epidemic trajectories using branching processes.
First, you need to estimate Rt over a recent time window
that you specify using t_start and t_end. When
estimating R and making projections in real time, there are very likely
to be people who have become symptomatic but are yet to have been
reported (known as right censoring). If you don’t use a method to
account for this then you will underestimate Rt, here we are
truncating the incidence so that the last week of data isn’t
included.
# Truncate the incidence to account for right censoring (e.g. 7 days)
trunc_date <- max(data$date_of_onset) - 7
trunc_linelist <- subset(data, data$date_of_onset < trunc_date)
# Create incidence object without last 7 days of data
trunc_incidence <- incidence(trunc_linelist$date_of_onset)
# Estimate R over a recent time window
Res <- estimate_R(incid = trunc_incidence,
method = "parametric_si",
config = make_config(mean_si = mean_si, std_si = std_si,
# 2 week window that ended a week ago
t_start = length(trunc_incidence) - 14,
t_end = length(trunc_incidence))) We can then supply the incidence, median estimate of R, and the SI
distribution to the project() function in the
projections package. Note: The project()
function requires that the distribution of the serial interval starts on
day 1, not on day 0 as in EpiEstim.
# Use the project function
proj <- project(trunc_incidence, # truncated incidence object
R = Res$R$`Median(R)`, # median R estimate
si = Res$si_distr[-1], # serial interval distribution (starts day 1)
n_sim = 1000, # number of trajectories to simulate e.g. 1000
n_days = 30, # number of days to make projections over e.g. 30
R_fix_within = TRUE) # keep the same value of R every day (TRUE/FALSE)You can then plot the incidence and use the pipe operator
%>% to add the projections with lower, median and upper
quantiles.
plot(trunc_incidence, xlab = "Date of Symptom Onset") %>% add_projections(proj, c(0.025, 0.5, 0.975))For a worked example, see example A. For more information on the
projections package see: https://www.repidemicsconsortium.org/projections/
Example A: Entire workflow
This example will take you through an entire workflow where we start
with incidence data, estimate Rt using a parametric serial
interval distribution and then make short term projections of future
incidence using the projections package. Here we will be
using a lot of the default parameters, but examples of how each of these
steps can be modified are shown in examples B-G.
We will be using the data from a simulated outbreak of Ebola Virus Disease (EVD) in West Africa, taken from https://www.reconlearn.org/post/real-time-response-1.html
Incidence
Let us say we have line list data in the format below, where each row corresponds to a reported case of EVD.
head(linelist)
#> case_id generation date_of_infection date_of_onset date_of_hospitalisation
#> 1 d1fafd 0 <NA> 07/04/2014 17/04/2014
#> 2 53371b 1 09/04/2014 15/04/2014 20/04/2014
#> 3 f5c3d8 1 18/04/2014 21/04/2014 25/04/2014
#> 4 6c286a 2 <NA> 27/04/2014 27/04/2014
#> 5 0f58c4 2 22/04/2014 26/04/2014 29/04/2014
#> 6 49731d 0 19/03/2014 25/04/2014 02/05/2014
#> date_of_outcome outcome gender hospital lon lat
#> 1 19/04/2014 <NA> f Military Hospital -13.21799 8.473514
#> 2 <NA> <NA> m Connaught Hospital -13.21491 8.464927
#> 3 30/04/2014 Recover f other -13.22804 8.483356
#> 4 07/05/2014 Death f <NA> -13.23112 8.464776
#> 5 17/05/2014 Recover f other -13.21016 8.452143
#> 6 07/05/2014 <NA> f <NA> -13.23443 8.468572We can create an incidence object for all the cases of EVD with a
known date of symptom onset (date_of_onset) using the
incidence package:
# linelist$date_of_onset is class 'character', but we need it to be a date:
linelist$date_of_onset <- as.Date(linelist$date_of_onset, format = "%d/%m/%Y")
# Create an incidence object:
evd_incid <- incidence(linelist$date_of_onset)
# Plot the incidence:
plot(evd_incid, xlab = "Date")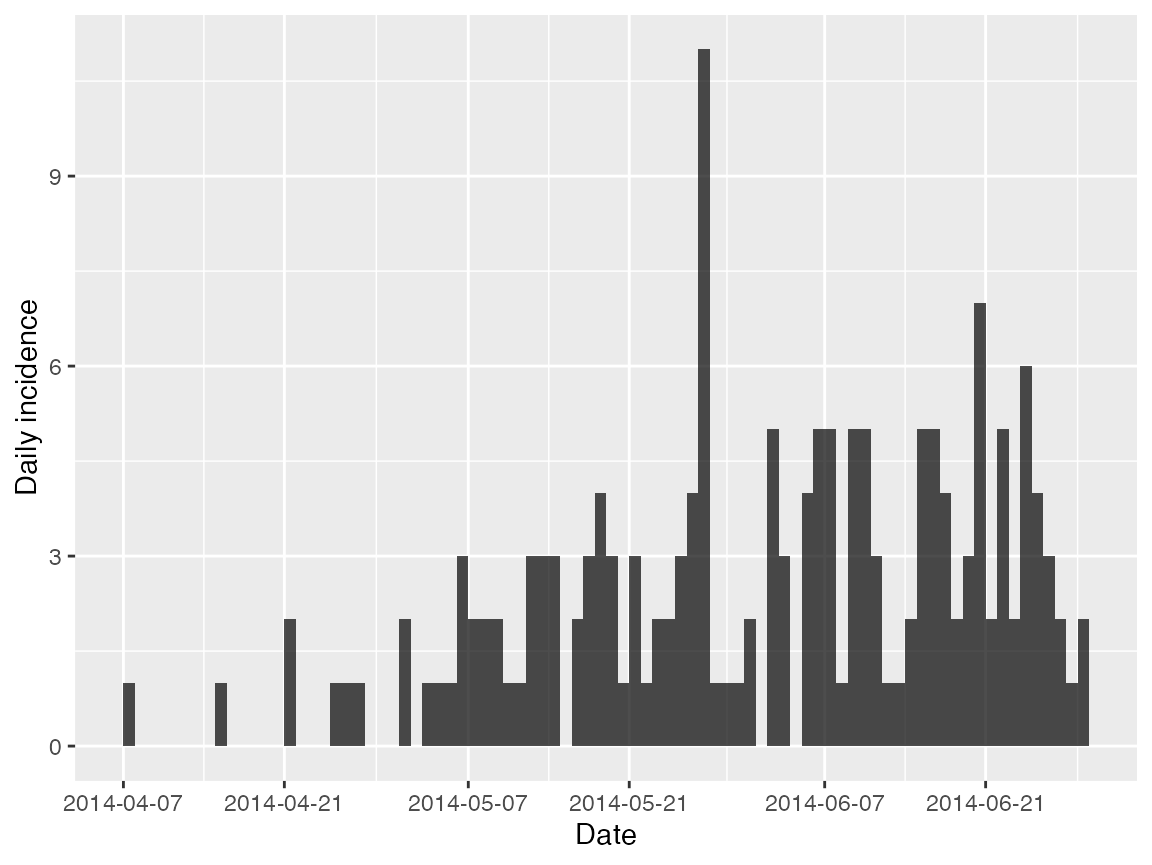
Estimate Rt using parametric SI distribution
Now that we have an incidence object we need to supply
EpiEstim with the SI distribution. As explained above, when
we estimate Rt using a parametric SI distribution we only
need to supply a mean and standard deviation. We will assume that the
mean of the SI distribution is 14.2 and that the SD is 9.6 using an
estimate found in the literature (WHO Ebola Response Team, 2015).
We supply estimate_R() with the incidence object and
parameters for the parametric SI and this generates the following 3
panel plot:
R_si_parametric <- estimate_R(incid = evd_incid,
method = "parametric_si",
config = make_config(mean_si = 14.2, std_si = 9.6))
plot(R_si_parametric, legend = FALSE)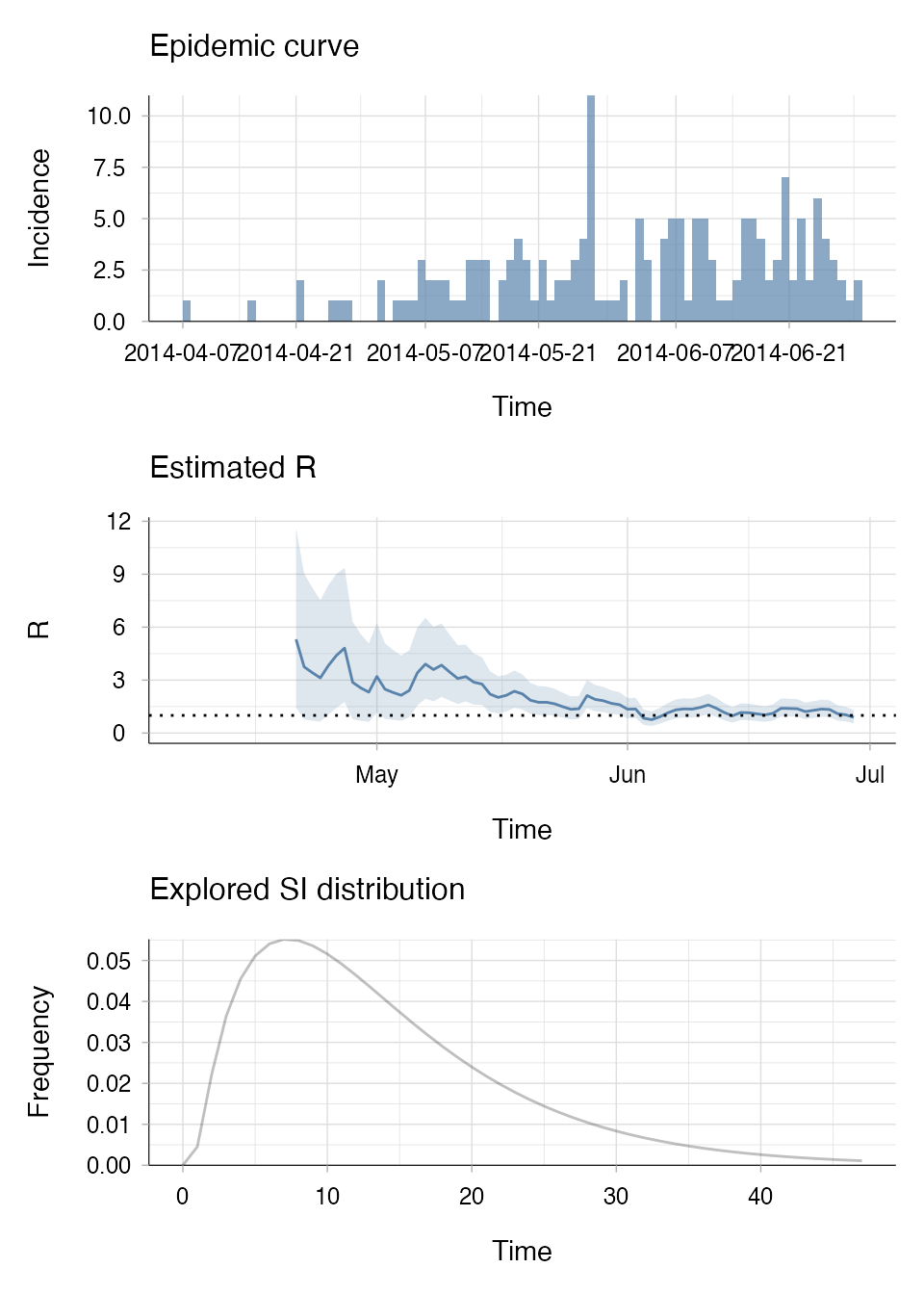
The top panel shows the epidemic curve with the incidence of reported cases over time. The middle panel is the estimated value of R over weekly sliding windows and how it varies over time (Rt), the mean is shown by the solid black line and the 95% credible intervals are represented by the grey shaded area. The final panel is the explored SI distribution that we parameterised and used to estimate Rt.
You will notice in the “Estimated R” panel that there is a lot of uncertainty around the initial estimates for Rt in the outbreak due to very little data. This is why we recommend that you do not try to estimate Rt until there have been at least 10 cases so that you can be confident that your estimates reflect the data (Cori 2013).
Make Projections
The projections package takes the estimated reproduction
number, serial interval distribution and incidence object to simulate
epidemic trajectories using branching processes. Note: The
project() function requires that the distribution of the
serial interval starts on day 1, not on day 0 as in EpiEstim.
# Truncate the linelist so that the last 7 days of data are not included
# (some people who have become symptomatic are yet to be reported)
trunc_date <- max(linelist$date_of_onset) - 7
trunc_linelist <- subset(linelist, linelist$date_of_onset < trunc_date)
# Create incidence object without last 7 days of data
evd_incid_trunc <- incidence(trunc_linelist$date_of_onset)
# Estimate R over a recent time window.
R_si_parametric_recent <- estimate_R(incid = evd_incid_trunc,
method = "parametric_si",
config = make_config(mean_si = 14.2, std_si = 9.6,
# 2 week window that ended a week ago:
t_start = length(evd_incid_trunc$counts) - 14,
t_end = length(evd_incid_trunc$counts)))
# Project future incidence over 30 days since last day in truncated incidence
proj <- project(evd_incid_trunc, # truncated incidence object
R = R_si_parametric_recent$R$`Median(R)`, # R estimate
si = R_si_parametric_recent$si_distr[-1], # SI (starting on day 1)
n_sim = 1000, # simulate 1000 trajectories
n_days = 30, # over 30 days
R_fix_within = TRUE) # keep the same value of R every day
# Add the projections over all incidence data
plot(evd_incid, xlab = "Date of Symptom Onset") %>%
add_projections(proj, c(0.025, 0.5, 0.975))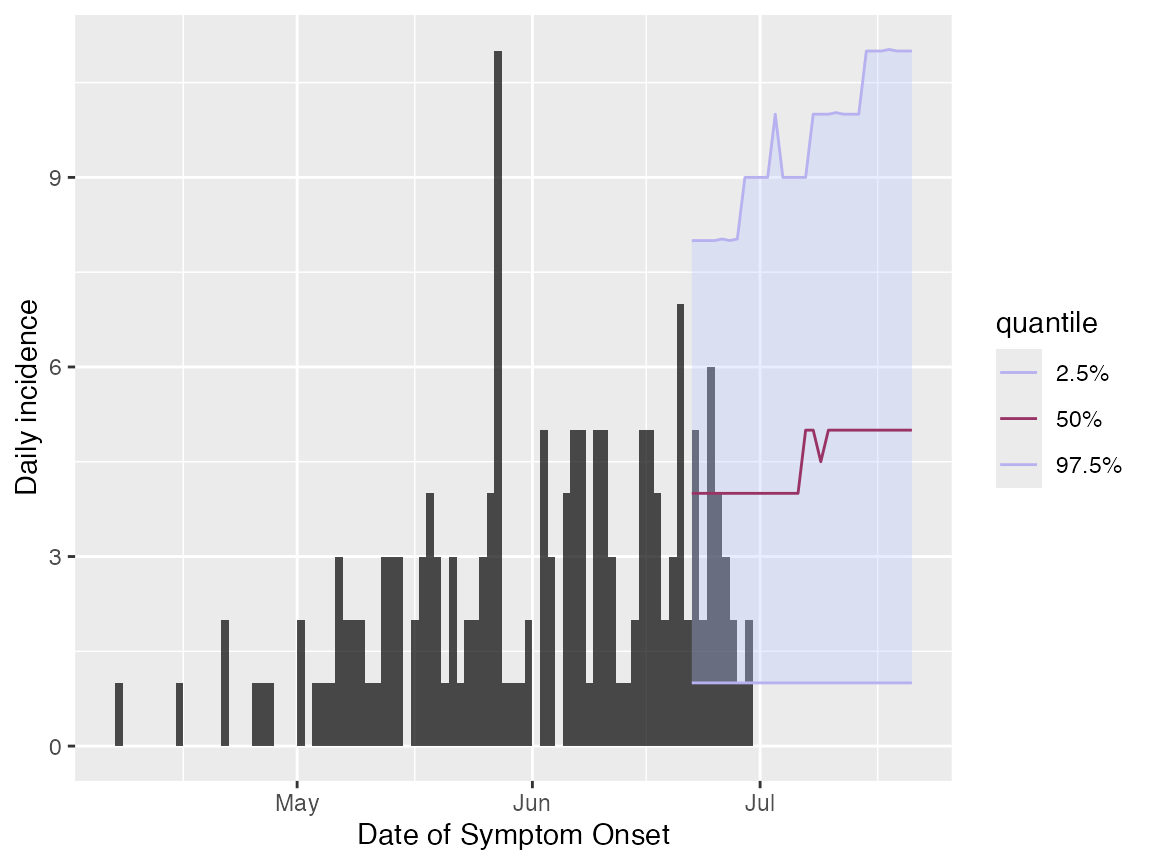
Here, we have plotted the original untruncated incidence object to illustrate that the projections have started over the uncertain week of data.
Example B: Estimating Rt using non-parametric distribution
If you want to supply a discrete SI distribution instead of a mean
and standard deviation, this can be done using method
non_parametric_si.
data(Flu2009) # example dataset within EpiEstim
# This dataset already has a discrete SI distribution:
Flu2009$si_distr
#> [1] 0.000 0.233 0.359 0.198 0.103 0.053 0.027 0.014 0.007 0.003 0.002 0.001
# Estimate R using non-parametric SI distribution:
R_np <- estimate_R(incid = Flu2009$incidence,
method = "non_parametric_si",
config = make_config(si_distr = Flu2009$si_distr))
plot(R_np, legend = FALSE)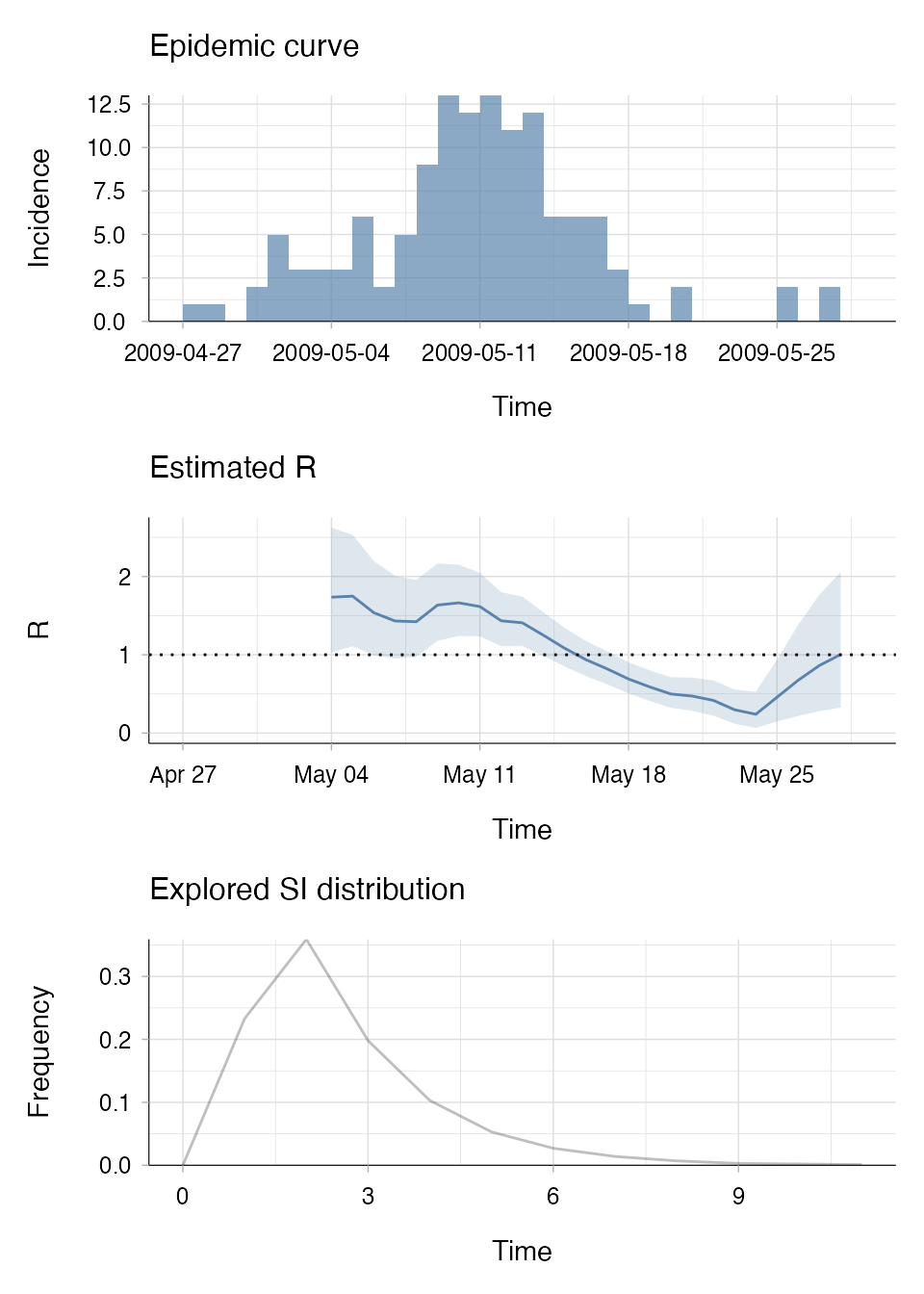
Example C: Estimating Rt using infector-infected cases
In this example we will be using a pre-loaded dataset for a mock outbreak of rotavirus. We have interval-censored data for symptom onset in infector-infected cases that can be used to estimate the SI distribution directly from the data.
data("MockRotavirus") # example dataset within EpiEstim
# Symptom onset data with upper and lower bounds that can be used to estimate
# the SI distribution
head(MockRotavirus$si_data)
#> EL ER SL SR type
#> 1 3 4 5 6 0
#> 2 5 6 8 9 0
#> 3 0 1 5 6 0
#> 4 5 6 7 8 0
#> 5 4 5 6 7 0
#> 6 5 6 8 9 0Here EL/ER are the lower/upper bounds for the day of symptom onset for the infector and SL/SR are the lower/upper bounds of the day of symptom onset for the infected individual. The last column “type” is optional and corresponds to whether the data is doubly interval-censored (0), single interval-censored (1) or exact observations (2), but if this is not supplied it will automatically be computed from the dates.
This can be used to estimate the SI distribution using MCMC:
# Configure the MCMC chain used to estimate the SI
mcmc_control <- make_mcmc_control(burnin = 1000, # first 1000 iterations discarded as burn-in
thin = 10, # every 10th iteration will be kept, the rest discarded
seed = 1) # set the seed to make the process reproducible
R_si_from_data <- estimate_R(incid = MockRotavirus$incidence,
method = "si_from_data",
si_data = MockRotavirus$si_data, # symptom onset data
config = make_config(si_parametric_distr = "gamma", # gamma dist. for SI
mcmc_control = mcmc_control,
n1 = 500, # number of posterior samples of SI dist.
n2 = 50, # number of posterior samples of Rt dist.
seed = 2)) # set seed for reproducibility
plot(R_si_from_data, legend = FALSE)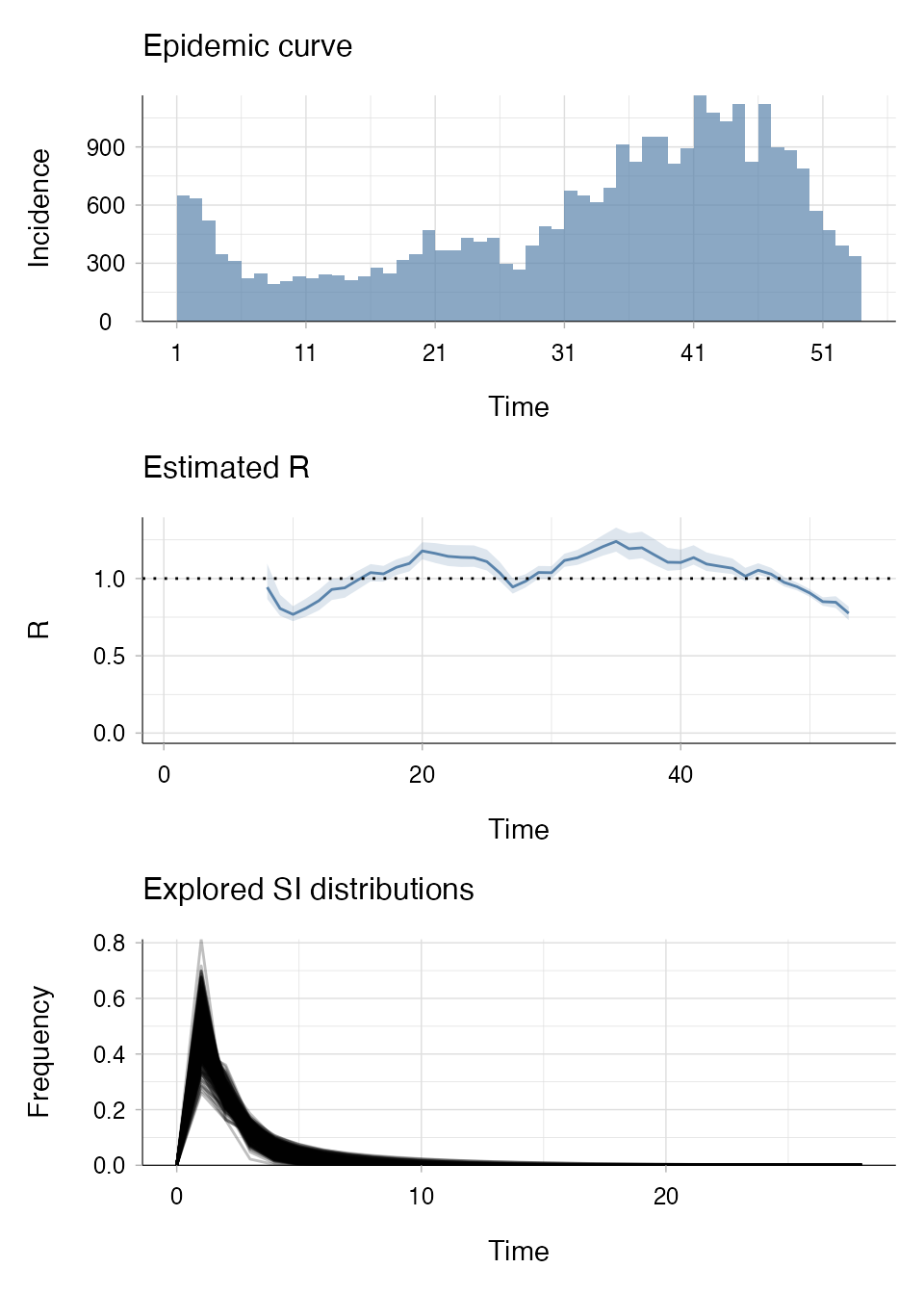
In this example, estimate_R() should take less than 20
seconds to run on a 2GHz 4 core computer (macOS Big Sur).
Note in the “Explored SI distributions” panel of the output that multiple distributions have been generated and are being explored.
Example D: Estimating Rt using “si_from_sample”
Running estimate_R() when using the method
si_from_data can take longer depending on the amount of
data you have. If you don’t want to re-estimate the SI each time you run
estimate_R() you can save the estimated SI distributions
and use the method si_from_sample instead.
# Take the R estimate object from Example C and extract the SI distribution
si_from_est <- R_si_from_data$si_distr
# Re-arrange the matrix so that each column corresponds to one SI distribution
# (t() simply transposes the data)
si_sample <- t(si_from_est)
# Estimate R using the "si_from_sample" method
R_samp <- estimate_R(incid = MockRotavirus$incidence,
method = "si_from_sample",
si_sample = si_sample)
plot(R_samp, legend = FALSE)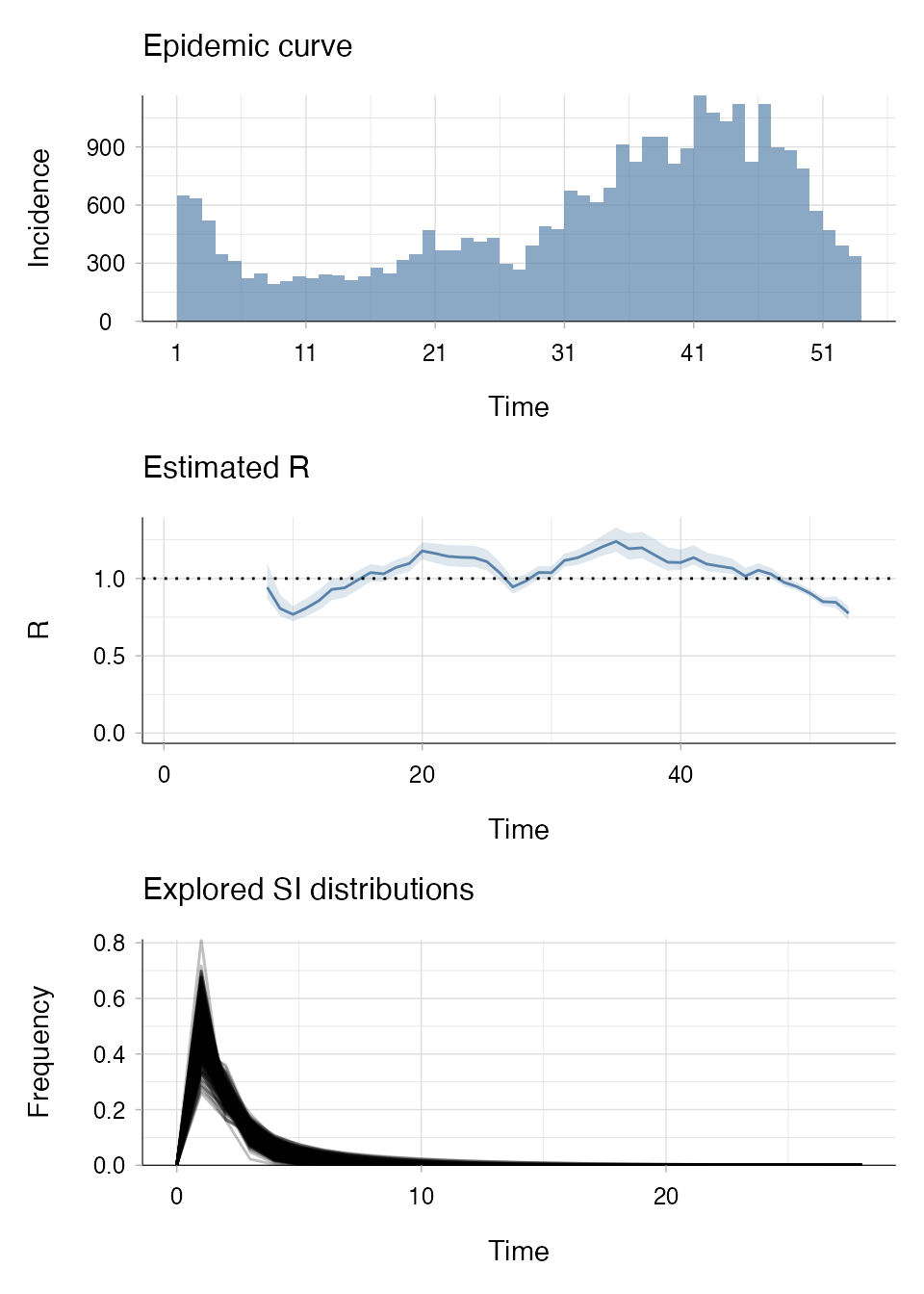
Here, estimate_R() using "si_from_sample"
takes less than 4 seconds to run on a 2GHz 4 core computer (macOS Big
Sur).
You can see that we’re estimating R from the same sample of SI distributions that were generated in example C and therefore getting the same result.
Example E: Estimating Rt using “uncertain_si”
If we pretend we don’t have data on infector-infected pairs for this
mock rotavirus outbreak, we might be pretty uncertain about the SI
distribution. We can choose to draw the mean and standard deviation of
the SI from truncated normal distributions that we parameterise based on
what we think the SI might look like using our current knowledge. This
means that estimate_R() would integrate results over each
SI drawn from these distributions of the mean and standard
deviation.
data("MockRotavirus")
R_si_uncertain <- estimate_R(incid = MockRotavirus$incidence,
method = "uncertain_si",
config = make_config(
mean_si = 2.5, std_mean_si = 2, # N(2.5,2) truncated at...
min_mean_si = 1.5, max_mean_si = 3.5, # 1.5 and 3.5
std_si = 1.5, std_std_si = 0.5, # N(1.5,0.5) trunc. at...
min_std_si = 0.5, max_std_si = 2.5)) # 0.5 and 2.5
plot(R_si_uncertain, legend = FALSE)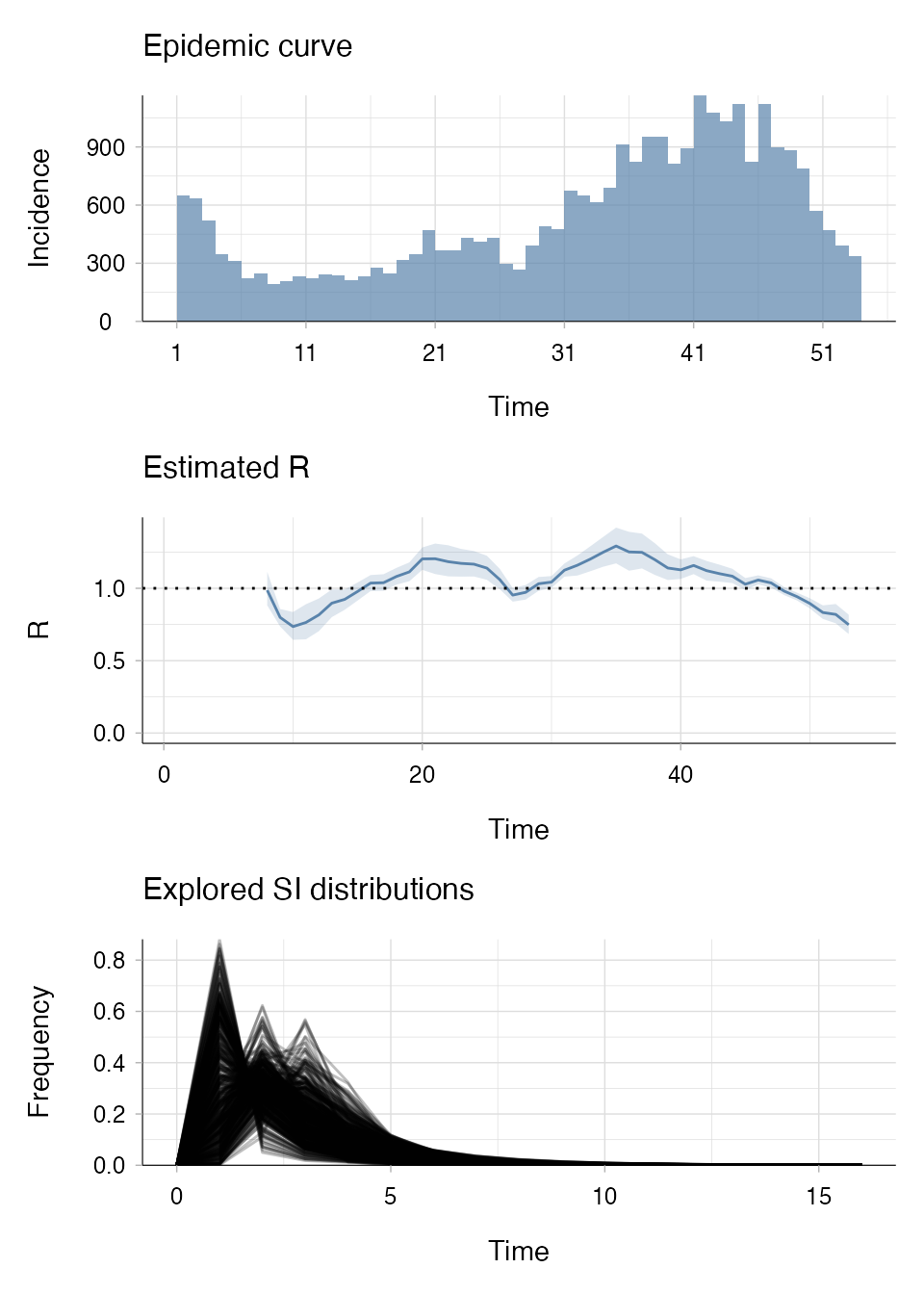
If you don’t want to draw the mean and standard deviation of the SI
from truncated normal distributions, you can perform the draws yourself
from alternative distributions and then supply the estimated SI
distributions to estimate_R() using the
si_from_sample method.
Example F: Changing the prior for estimating Rt
If we go back to example A you will notice that the initial R estimate in the “Estimated R” panel output is very high. When there is less data, the prior for R will have more weight on the value of the estimate. This example shows you how to modify the prior and the impact it can have on the initial estimate for R.
R_diff_prior <- estimate_R(incid = evd_incid,
method = "parametric_si",
config = make_config(mean_si = 14.2, std_si = 9.6,
mean_prior = 2, std_prior = 1))
plot(R_diff_prior, "R", legend = FALSE)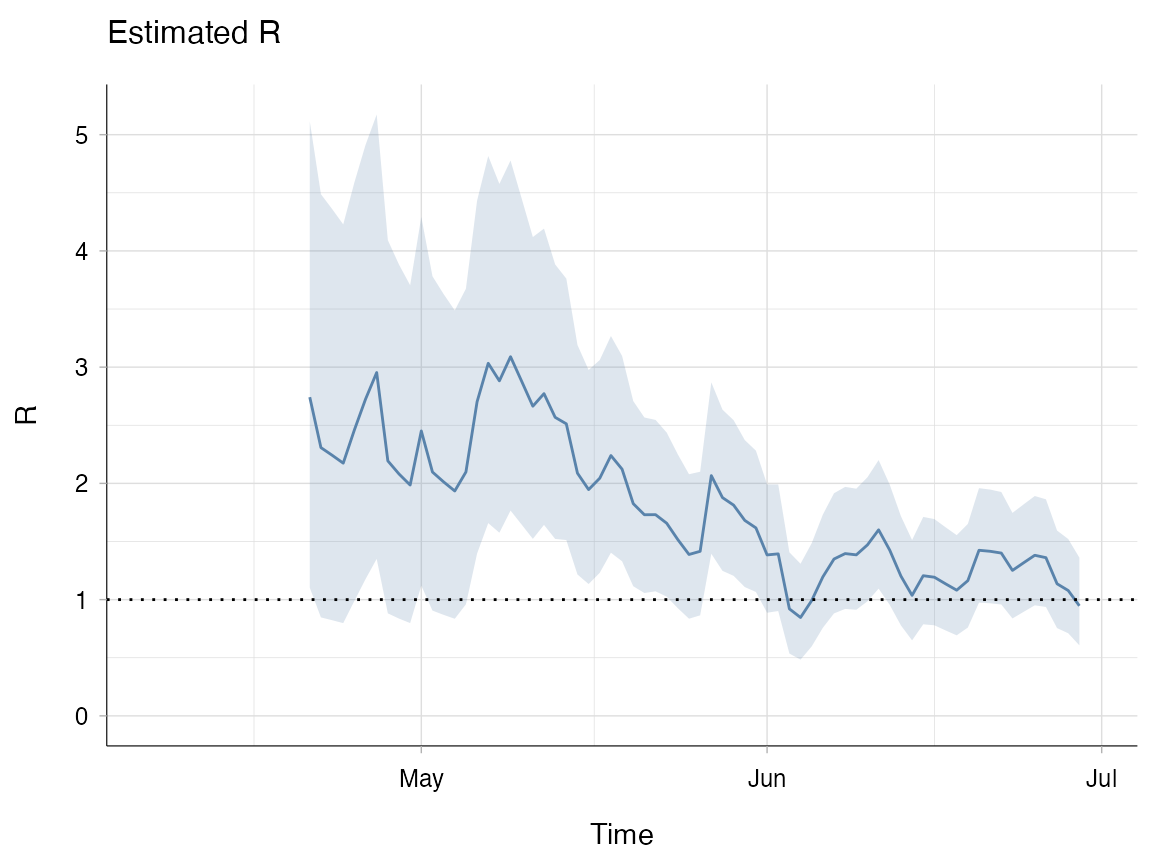
Below, both the estimate with the default prior from example A and the modified prior from this example are plotted together. After changing the prior to a mean of 2 and standard deviation of 1 the initial estimate for Rt is lower than the initial estimate using the default prior. Once there is more data (mid-May) the R estimates converge regardless of the prior. It is important to be aware of the weight the prior can have on your estimate when incidence is low.
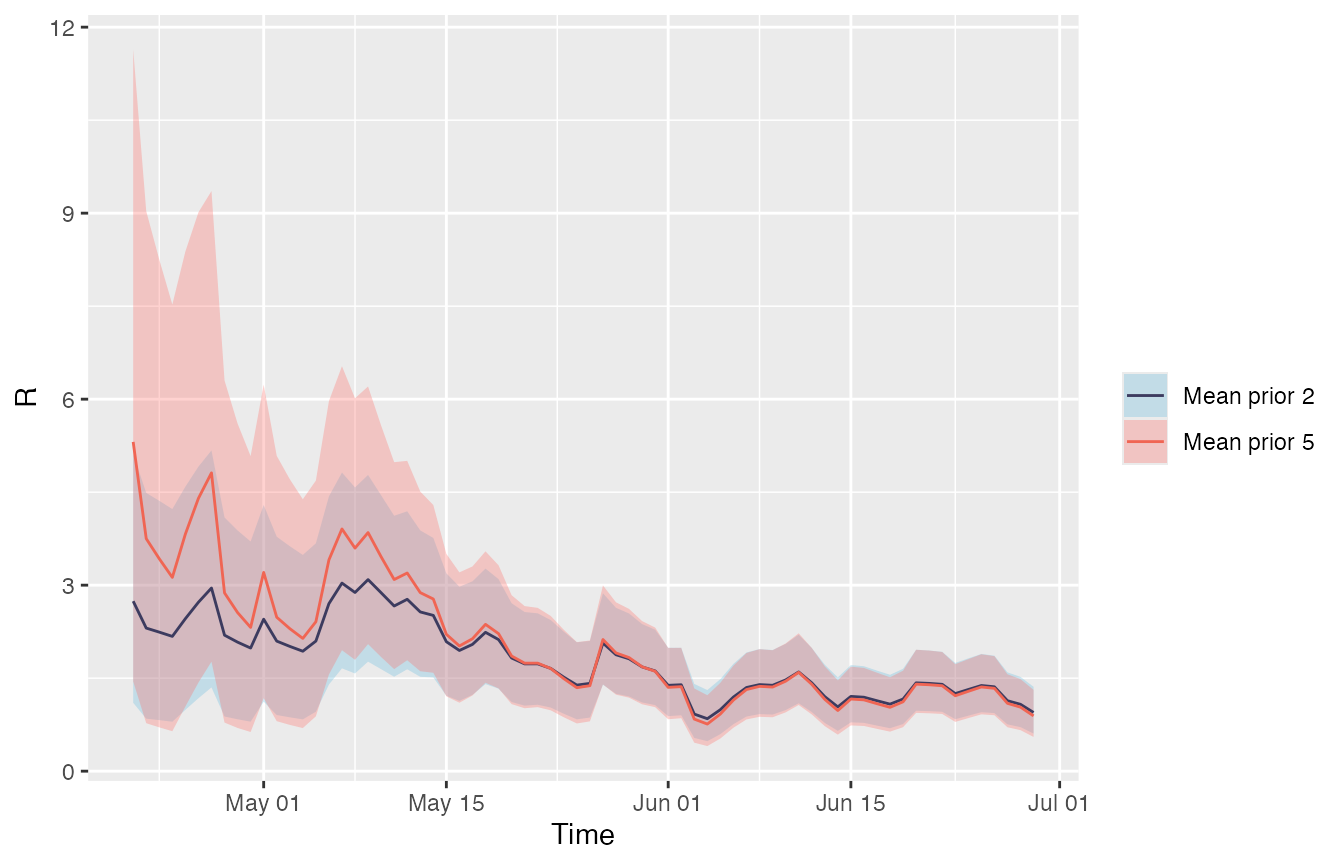
Example G: Changing the time window to estimate Rt
If we take the data from example A again, we could estimate Rt over three-week windows instead of the weekly windows used as the default.
# t_start` is a sequence of start days for the sliding window, starting on day 2
# ending 3 weeks before the last day in the dataset:
t_start <- seq(2, nrow(evd_incid) - 20)
# `t_end` is a sequence of end dates for the window 3 weeks after each start
# date defined above:
t_end <- t_start + 20
R_window <- estimate_R(incid = evd_incid,
method = "parametric_si",
config = make_config(mean_si = 14.2, std_si = 9.6,
t_start = t_start,
t_end = t_end))
plot(R_window, legend = FALSE, "R")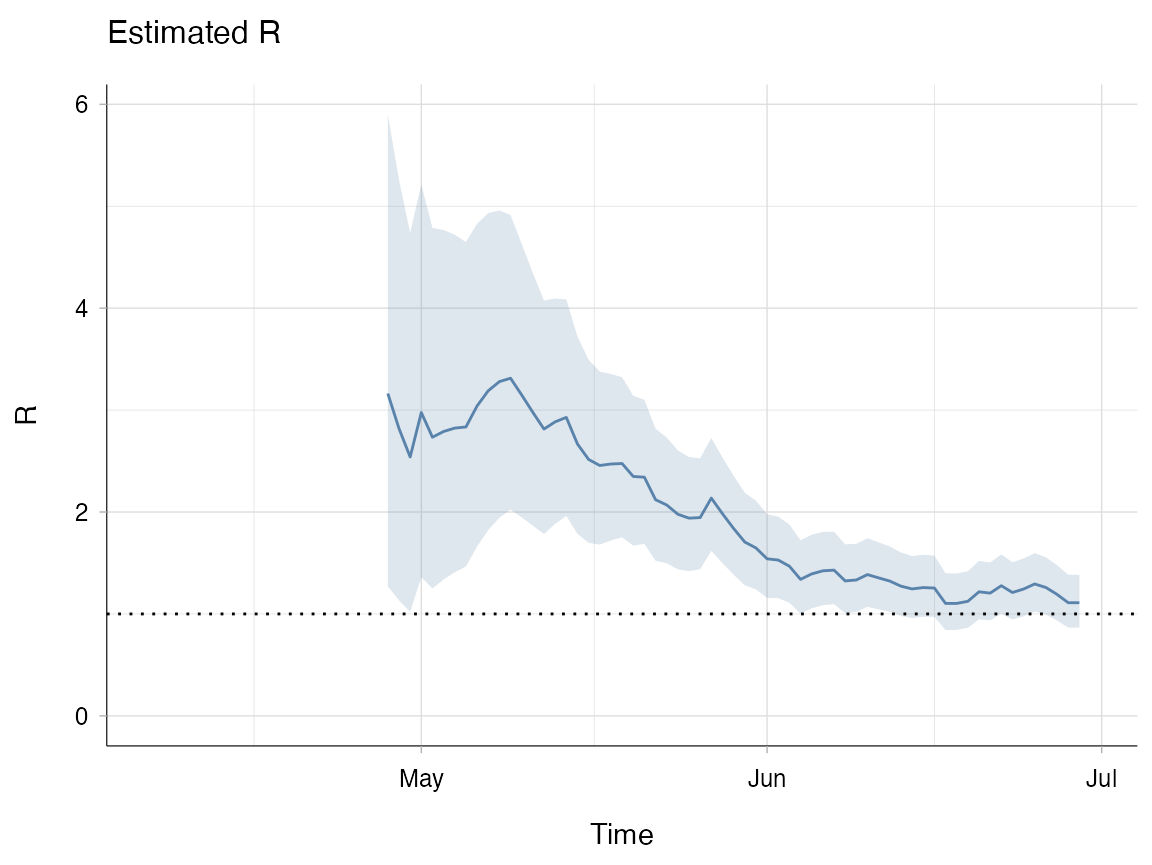
Below, the R estimates from example A (with the default weekly time windows) are plotted against the estimates made using three-week windows. Notice that because R has been estimated over longer time windows, the estimates for Rt are smoother than the estimates made in example A.
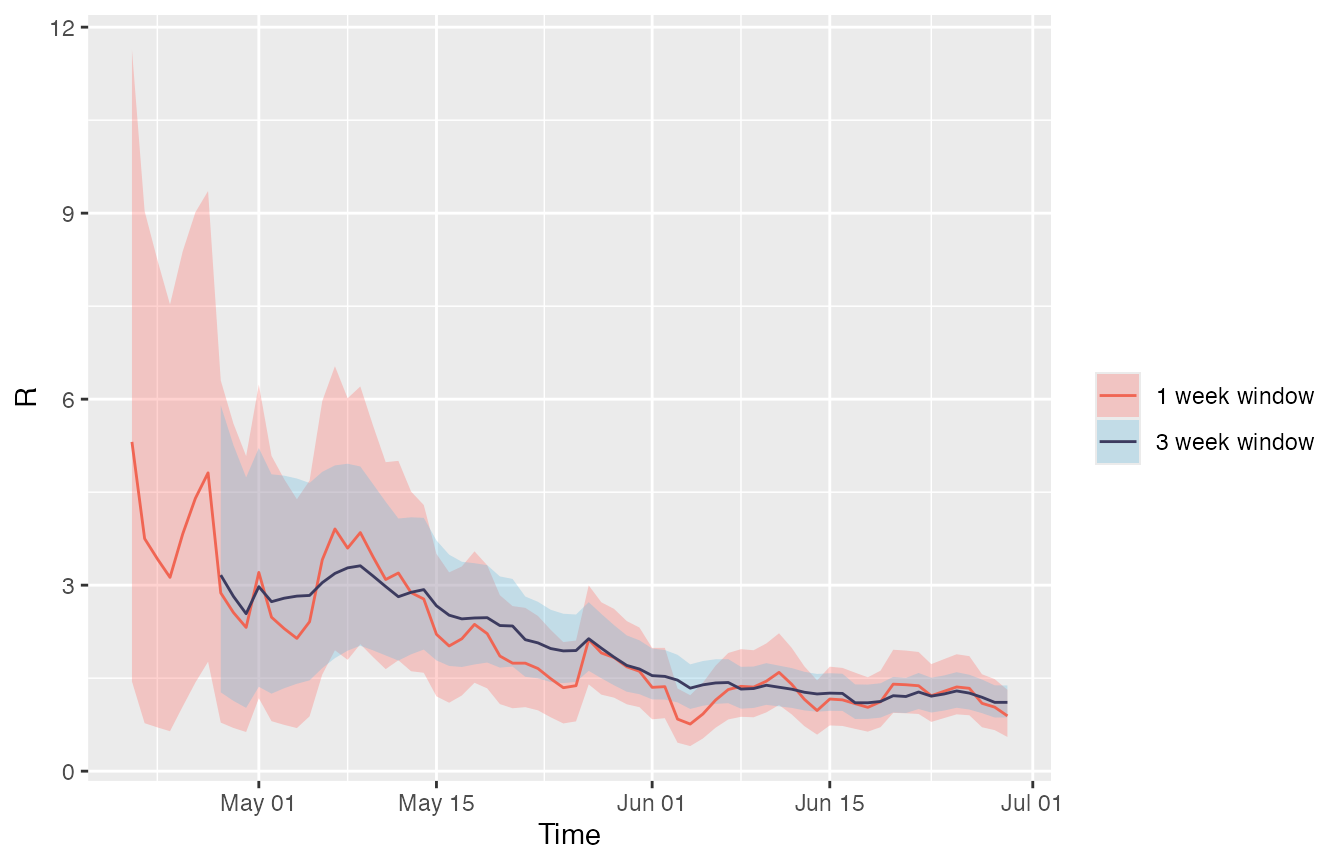
Remember that Rt is plotted on the last day of each time window, so although the estimation starts at the same time, the estimation for the three-week window appears to start later.
-
What if there are delays in the reporting of cases?
During an outbreak there tends to be a delay in the reporting of cases, which is known as right censoring. I.e. There are often cases with a recent symptom onset date that are yet to be reported, so the latest incidence is under-estimated when you’re analysing data in real-time. If you estimate Rt without accounting for this delay, then it could make Rt appear lower than it actually is. This is why in Example A we have chosen to not include the last 7 days of data in the recent time window used to estimate R and make projections.
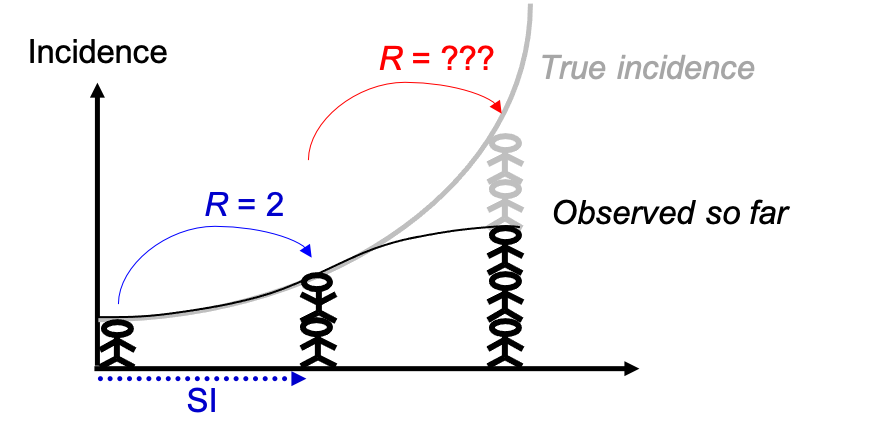
Figure courtesy of Anne Cori
-
What if the probability of cases being reported varies over time?
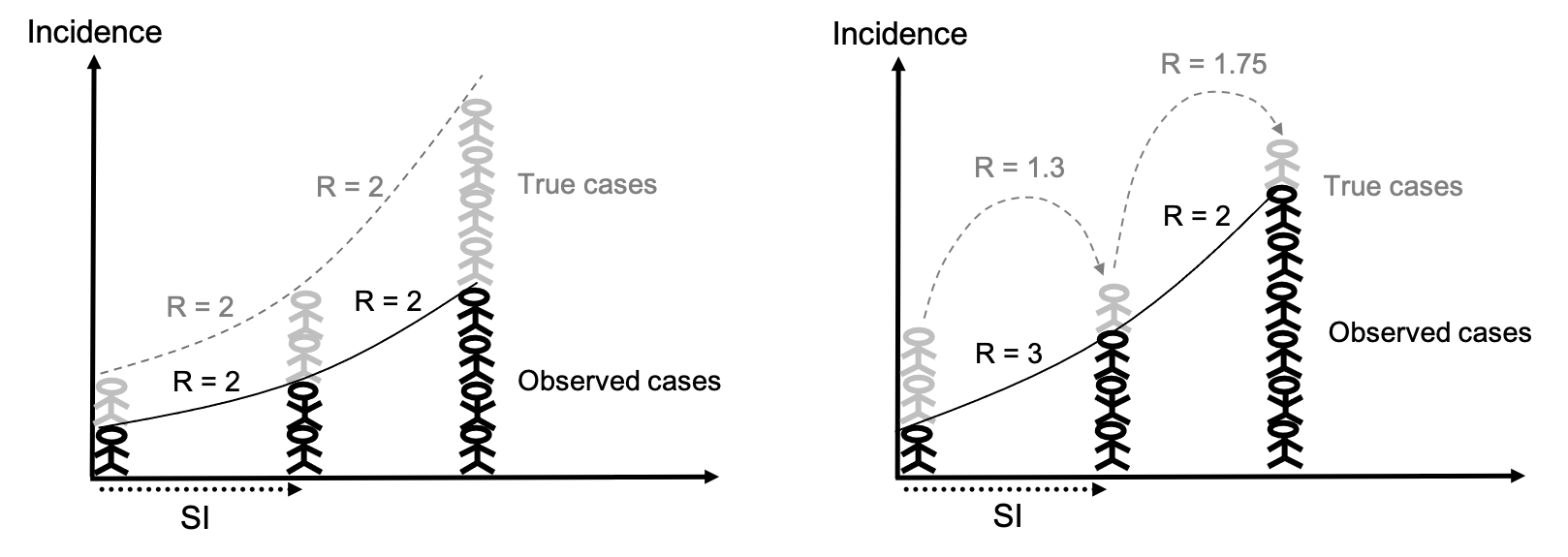
If the probability of a case being reported remains the same over time, then even if the true incidence is different to what is observed, the change in the “true” value of R should be consistent with the change in the observed value of R. If the probability of a case being reported changes over time, e.g. if testing capacity improves or fluctuates, then it is likely that the changes in the observed value of R will be biased.
Ex. If the probability of a case being reported is 0.5 (50% of cases reported), and that remains constant over the course of an outbreak, then the changes in the “true” and observed value of R will be consistent (left). If the probability of being reported improves, e.g. from 0.33 to 0.75 to 0.86, then changes in the estimated value of R will be biased (right).
-
Why are the estimates of R from
estimate_R()different from what I expect?estimate_R()uses a Bayesian estimation method, so the result depends on the data and also on the prior set for Rt. See Cori 2013 and Thompson 2019 for more details on the method used. As shown in the “Prior for Rt” section above, you can change the default prior using themake_configargument within theestimate_R()function. You can check whether your estimates are primarily data driven by runningestimate_R()with an alternative prior and assessing whether the results are dramatically different or not. This is more likely to be the case if you have less data. -
What are some important considerations for the choice of prior for Rt?
The default prior for Rt is set to a mean of 5 and standard deviation of 5. This is a very large Rt value, but the reason for this choice is to ensure that epidemics won’t appear under control unless the data really suggested that. However, this means that when there is less data, e.g. towards the end of the epidemic, you will simply recover whatever you have set your prior as, and if using the default values, Rt will appear very high. The larger the standard deviation you choose the less informative your prior is.
-
What should I be aware of when choosing a time window to estimate Rt?
Too large a time window may result in over-smoothing, which may miss important changes. Whereas, too small a time window may mean that estimates are more influenced by random noise in the data. As a general rule, if you have low incidence it is better to use a larger window to improve the robustness of your estimate. It is also quite typical for there to be a lower level of reporting on weekends compared to weekdays, so you should choose a time window that encompasses at least a week to smooth out the weekend effects.
-
Why is
estimate_R()taking so long to run?If you are using the method “
uncertain_si” to estimate the SI distribution,estimate_R()will take longer to run if the values forn1andn2are high. It can also take longer to run if using the method “si_from_data” as you are estimating the SI from your data at the same time as estimating Rt. We recommend that where possible you save the SI distribution estimated from your data and then supply this using the method “si_from_sample” so that you don’t have to re-estimate the SI each time you runestimate_R(). -
Can I use EpiEstim to estimate R from aggregated data e.g. weekly data?
Yes! Please see the ‘EpiEstim_aggregated_data’ vignette for further details.
References
Cori A, Ferguson NM, Fraser C, Cauchemez S. A New Framework and Software to Estimate Time-Varying Reproduction Numbers During Epidemics. Am J Epidemiol. 2013 Nov 1;178(9):1505–12.
Thompson R, Stockwin J, van Gaalen RD, Polonsky J, Kamvar Z, Demarsh P, et al. Improved inference of time-varying reproduction numbers during infectious disease outbreaks. Epidemics. 2019;29:100356.
Nouvellet P, Cori A, Garske T, Blake IM, Dorigatti I, Hinsley W, et al. A simple approach to measure transmissibility and forecast incidence. Epidemics. 2018;22:29–35.
WHO Ebola Response Team. West African Ebola Epidemic after One Year — Slowing but Not Yet under Control. New England Journal of Medicine. 2015 Feb 5;372(6):584–7.