Warning in odin2::odin({: Found 2 compatibility issues
Replace calls to 'user()' with 'parameter()'
✖ sd <- user()
✔ sd <- parameter()
Replace calls to r-style random number calls (e.g., 'rnorm()') with monty-stye
calls (e.g., 'Normal()')
✖ update(y) <- y + rnorm(0, sd)
✔ update(y) <- y + Normal(0, sd)Future of the tools
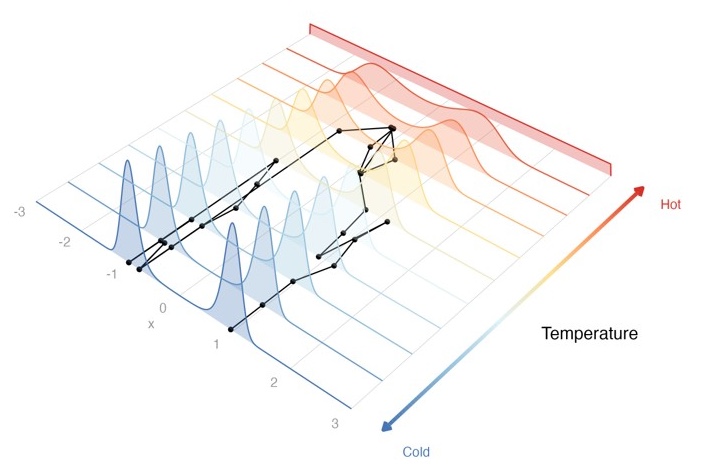
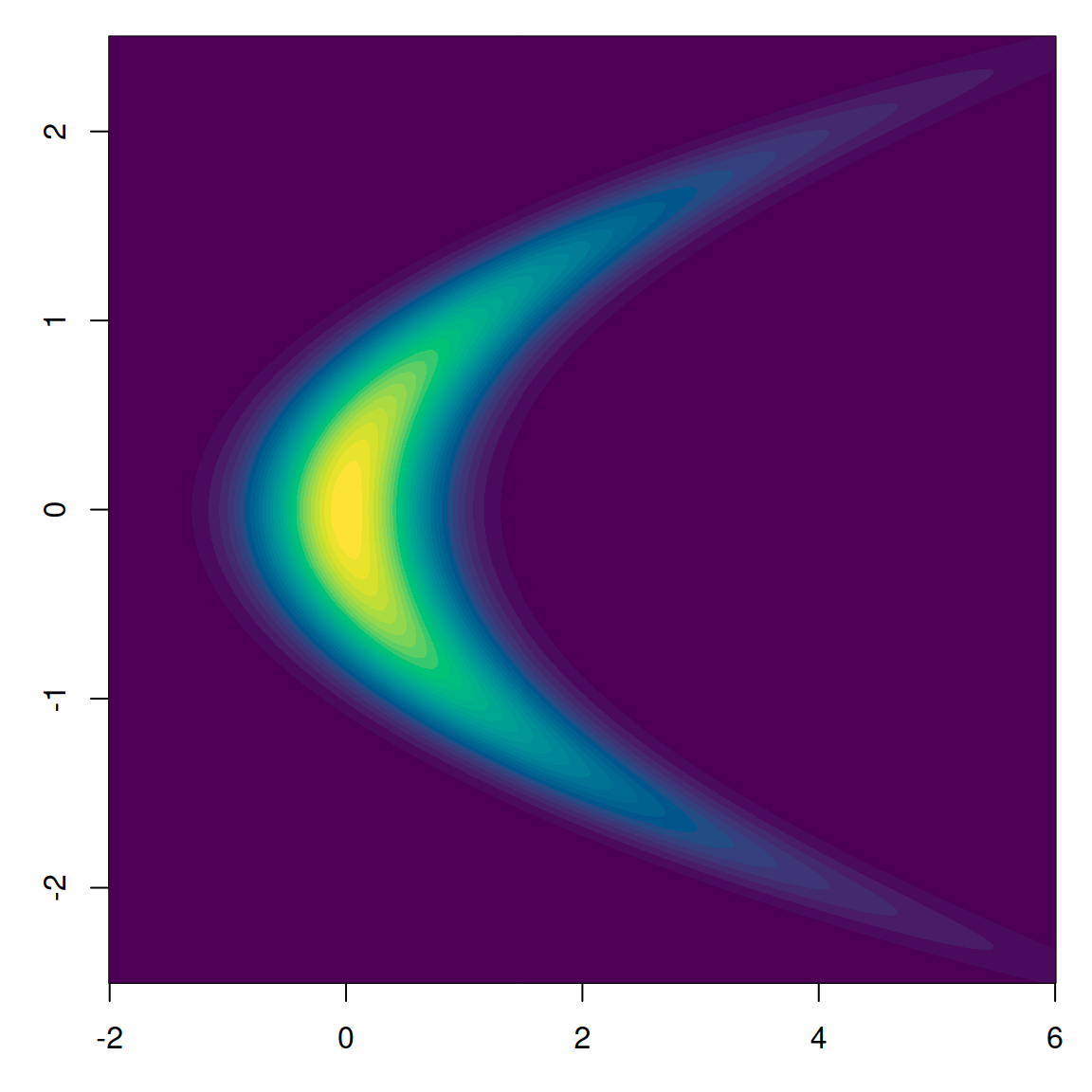
🍌 The Banana Problem
- This posterior has a strong nonlinear correlation
- Random walk proposals struggle to explore this space
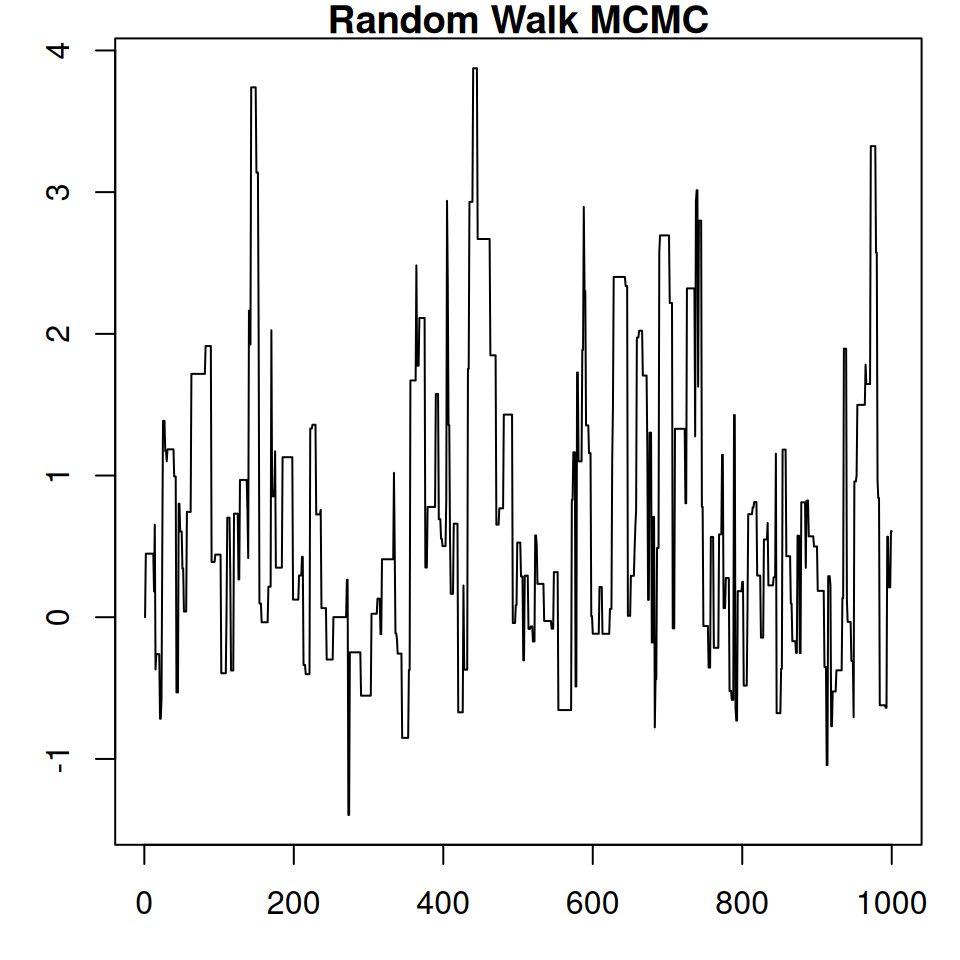
🐢 Random Walk MCMC: Limitation
set.seed(42)
sampler_rw <- monty_sampler_random_walk(vcv = diag(2)*1.5)
samples_rw <- monty_sample(m, sampler_rw, n_steps = 1000, initial = c(0,0))⡀⠀ Sampling ■ | 0% ETA: 3s✔ Sampled 1000 steps across 1 chain in 42ms- Acceptance rate 0.236
- Small steps to avoid rejection → slow mixing
- Misses curved geometry
- Inefficient in higher dimensions
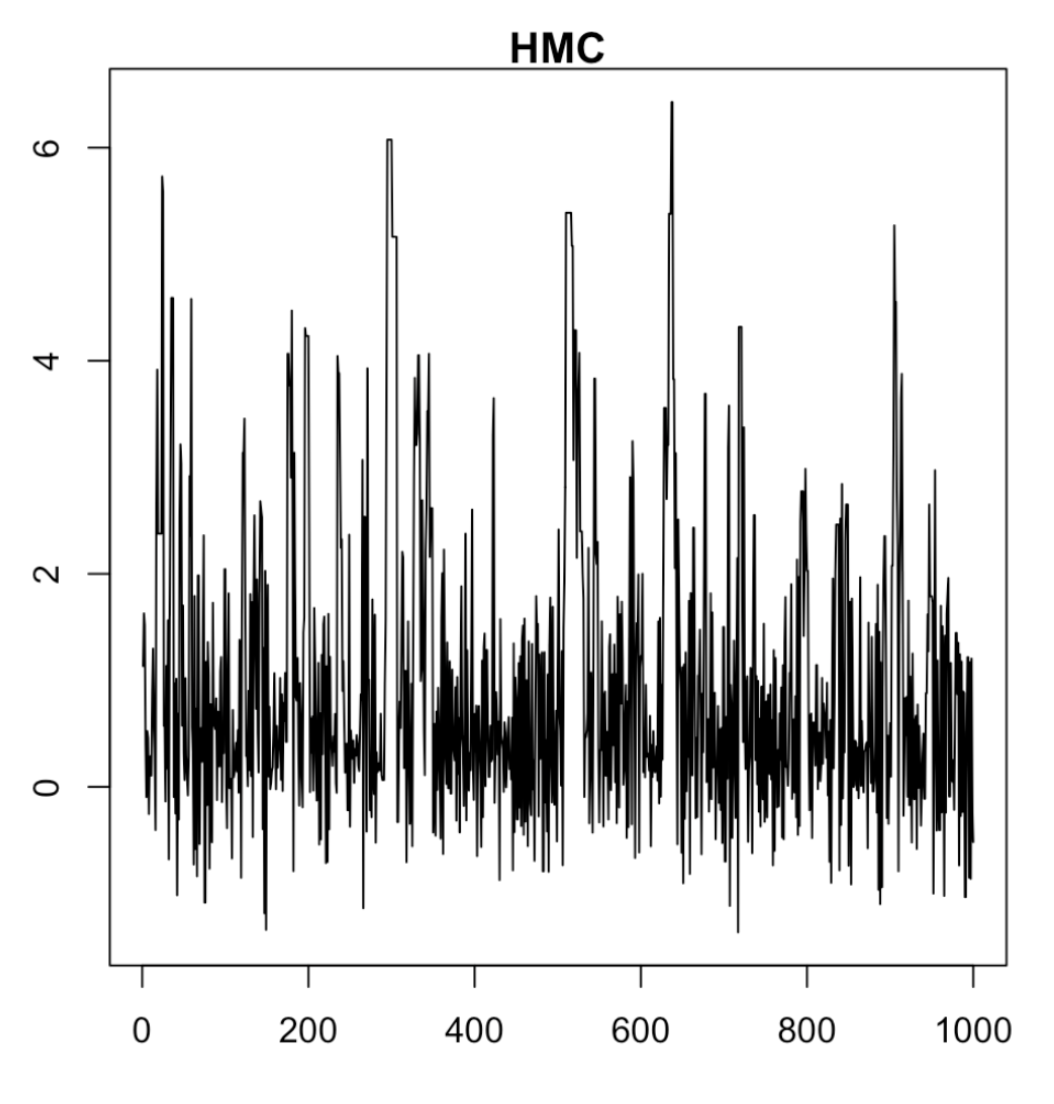
⚡ Gradient-Based: Faster & Smarter
- Acceptance rate 0.236
- Uses gradient of the log posterior
- Efficiently explores curved shapes
- Much better mixing in fewer steps
- But potentially expensive to compute gradients
Parallel tempering