mcstate
Can you be more precise?
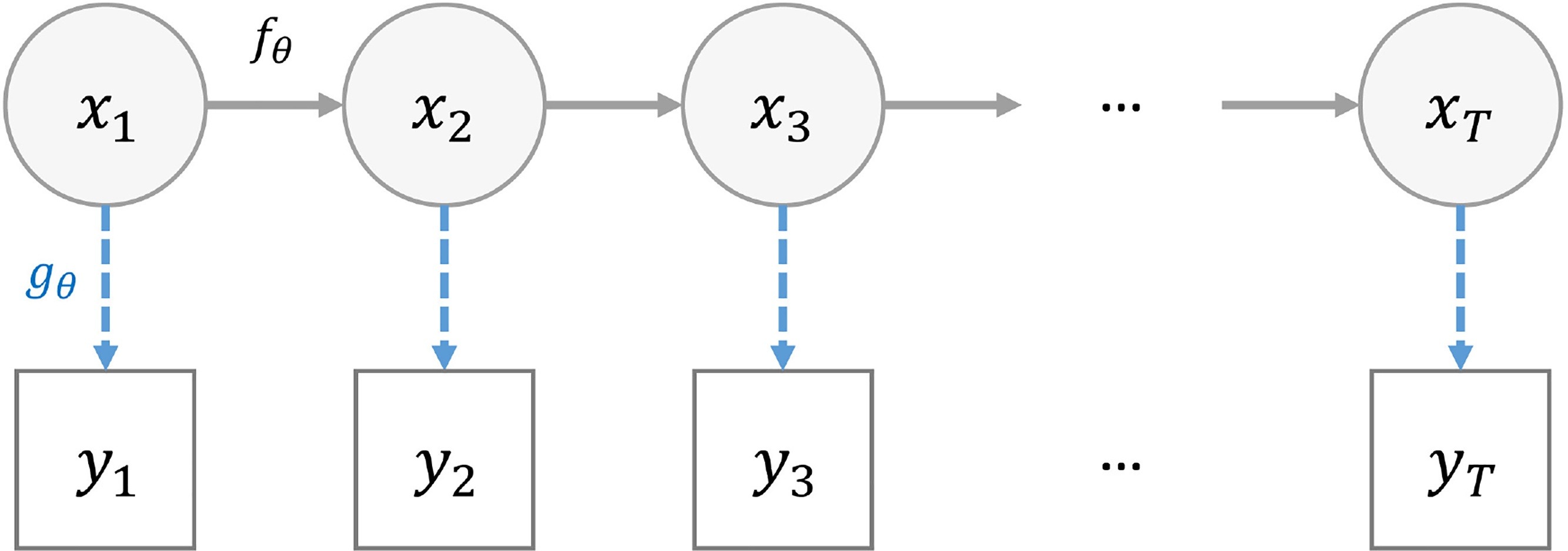
- \(x_{t, 1 \leq t \leq T}\) the hidden states of the system
- \(y_{t, 1 \leq t \leq T}\) the observations
- \(f_{\theta}\) the state transition function
- \(g_{\theta}\) the observation function
- \(t\) is often time
- \(\theta\) defines the model
Two common problems
- Two common needs
- “Filtering” i.e. estimate the hidden states \(x_{t}\) from the observations \(y_t\)
- “Inference” i.e. estimate the \(\theta\)’s compatible with the observations \(y_{t}\)
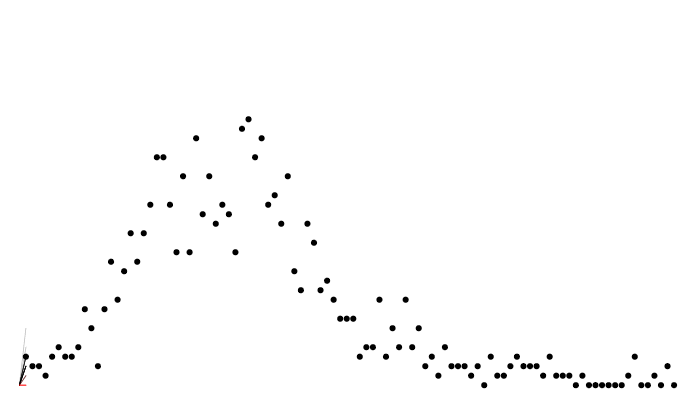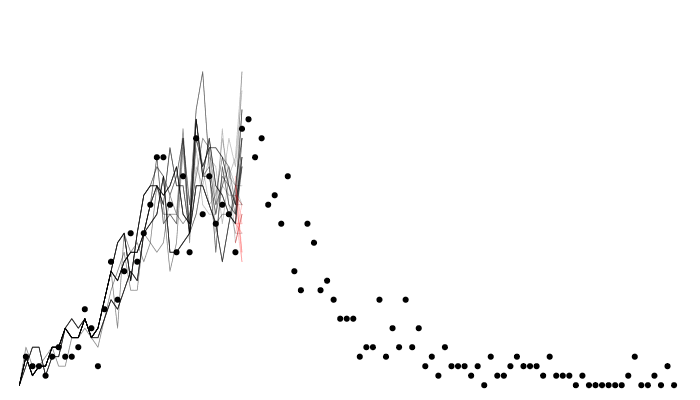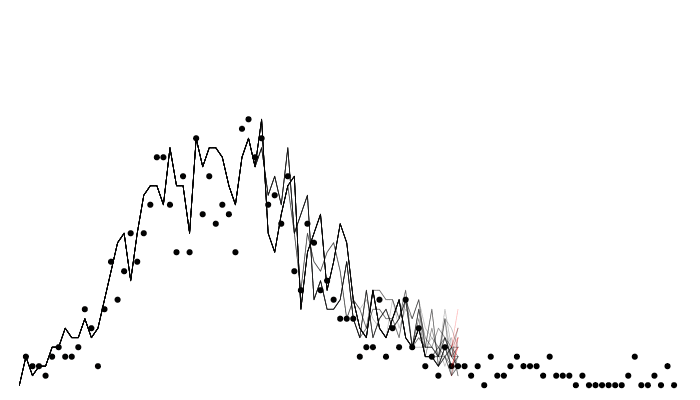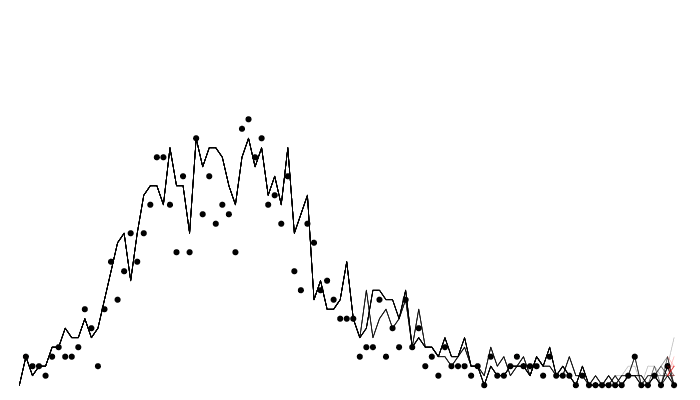
The filter in action
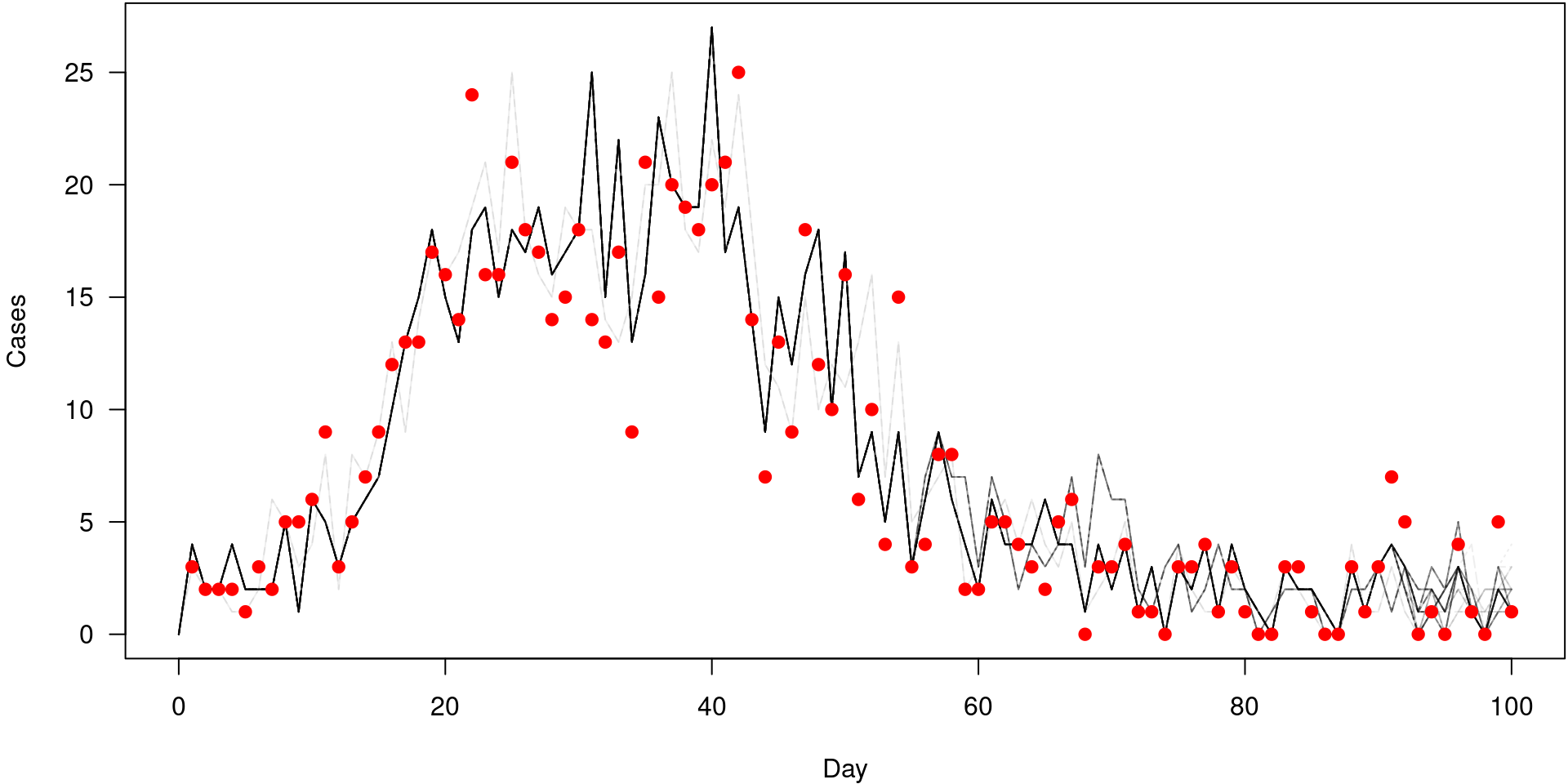
The data
cases day
1 3 1
2 2 2
3 2 3
4 2 4
5 1 5
6 3 6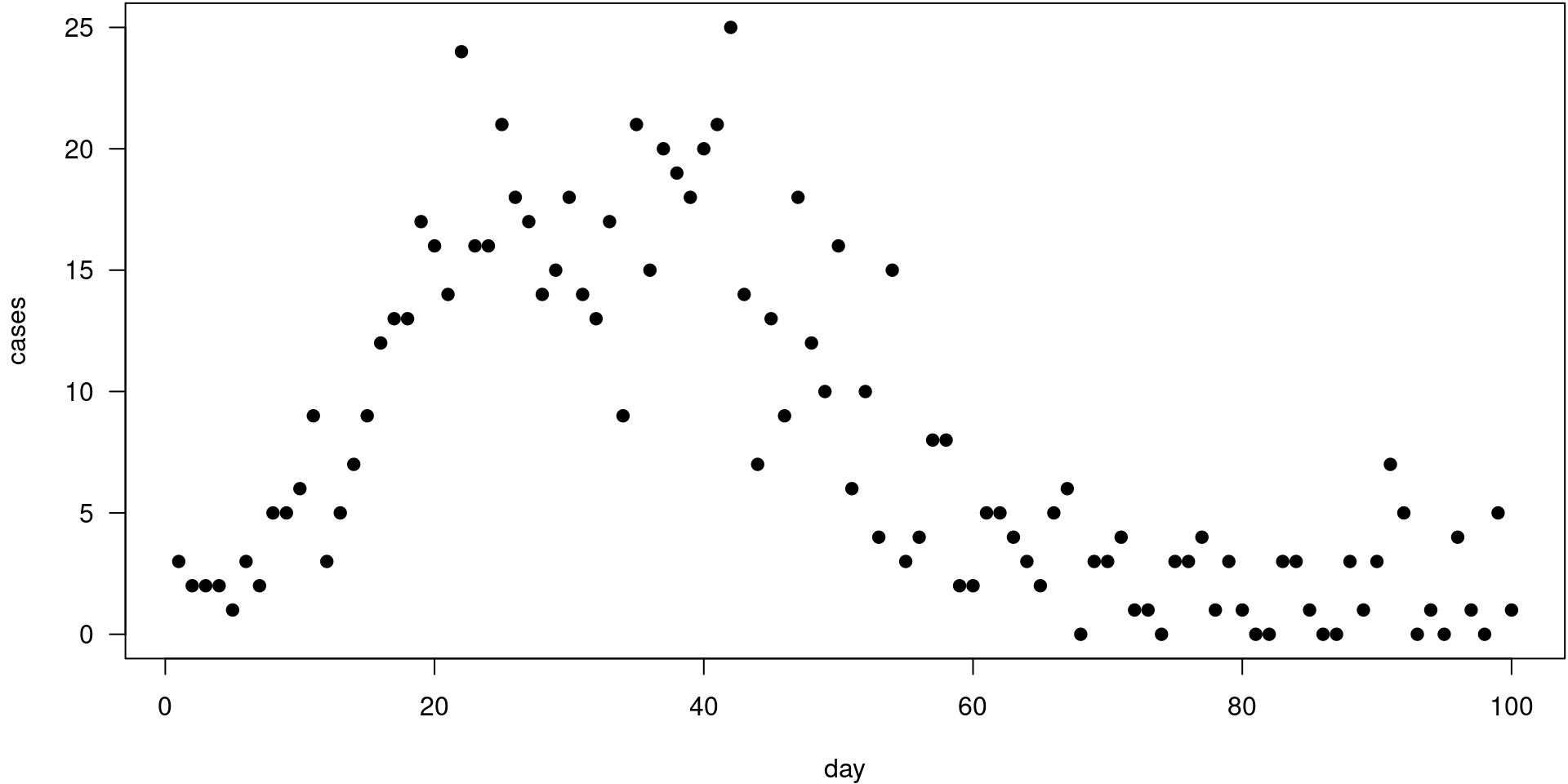
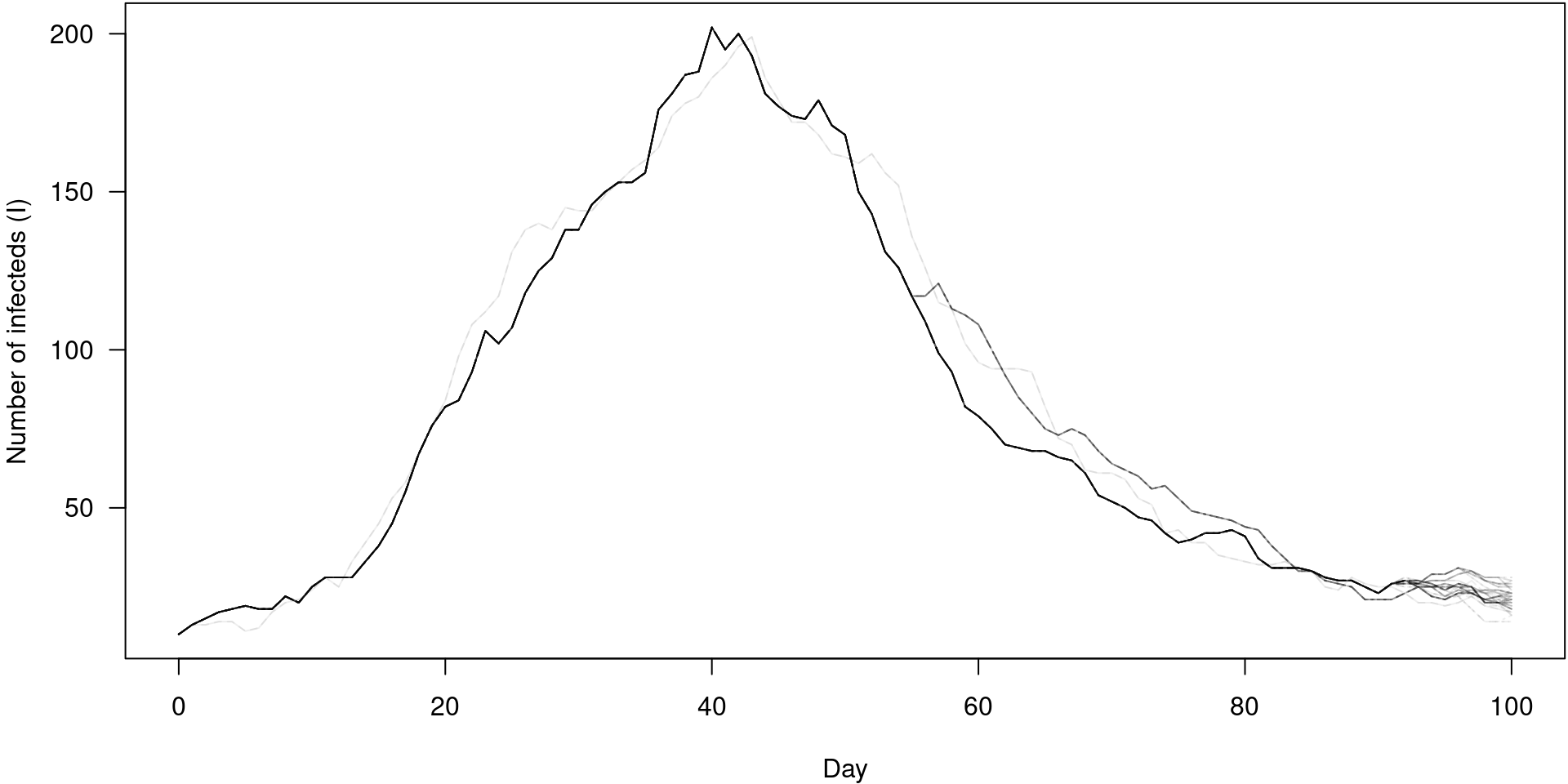
The model over time
pars <- list(beta = 0.25, gamma = 0.1)
mod <- sir$new(pars, 0, 20)
y <- mod$simulate(c(0, data$time_end))
i <- mod$info()$index[["time"]]
j <- mod$info()$index[["cases_inc"]]
matplot(y[i, 1, ], t(y[j, , ]), type = "l", col = "#00000055", lty = 1, las = 1,
xlab = "Day", ylab = "Cases")
points(cases ~ day, incidence, col = "red", pch = 19)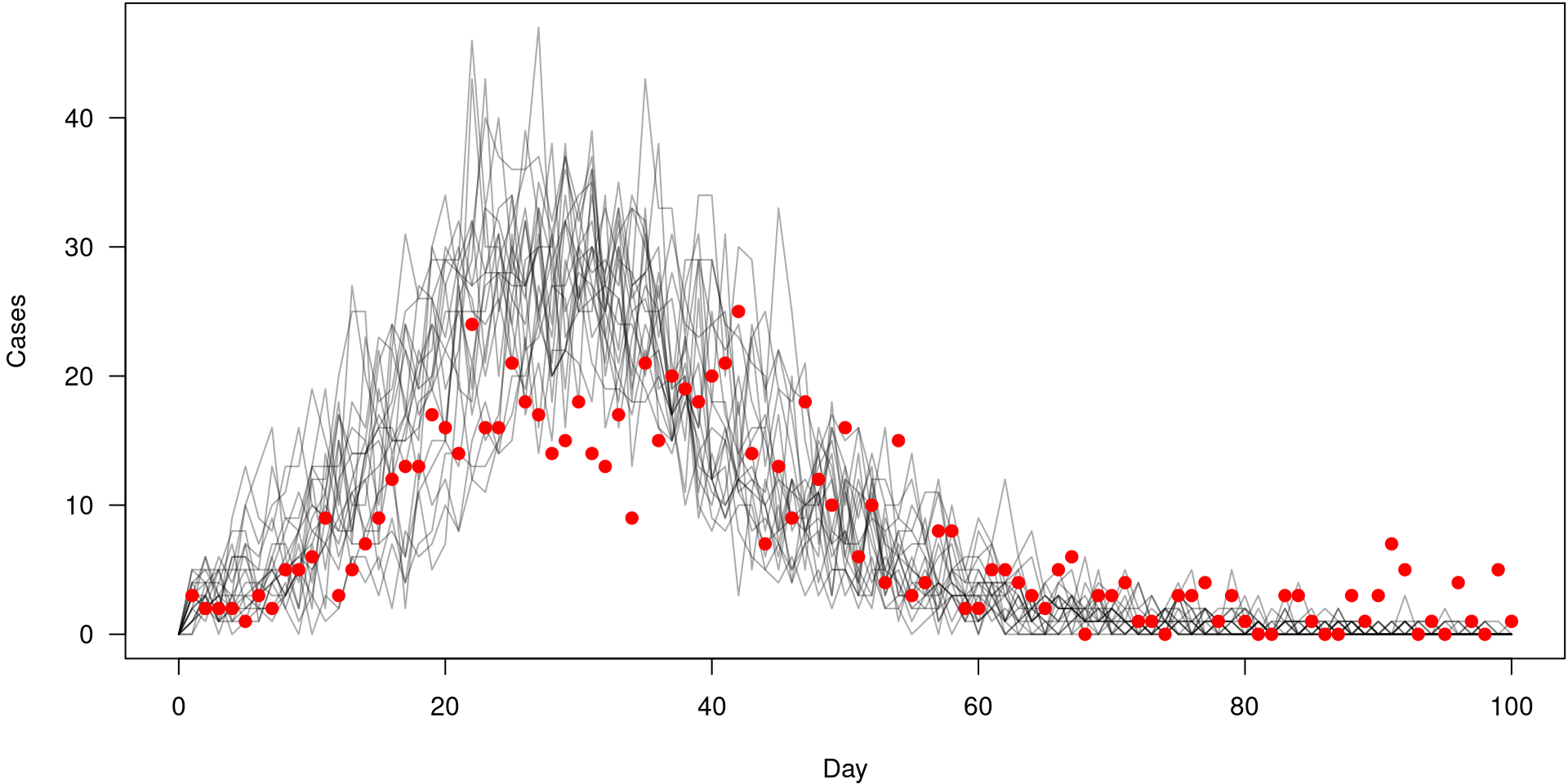
The compare function
This is the important bit, and something that is a trick to write well.
Particle filter history is a tree
Particle filter history for unobserved states
Our PMCMC samples
oh.
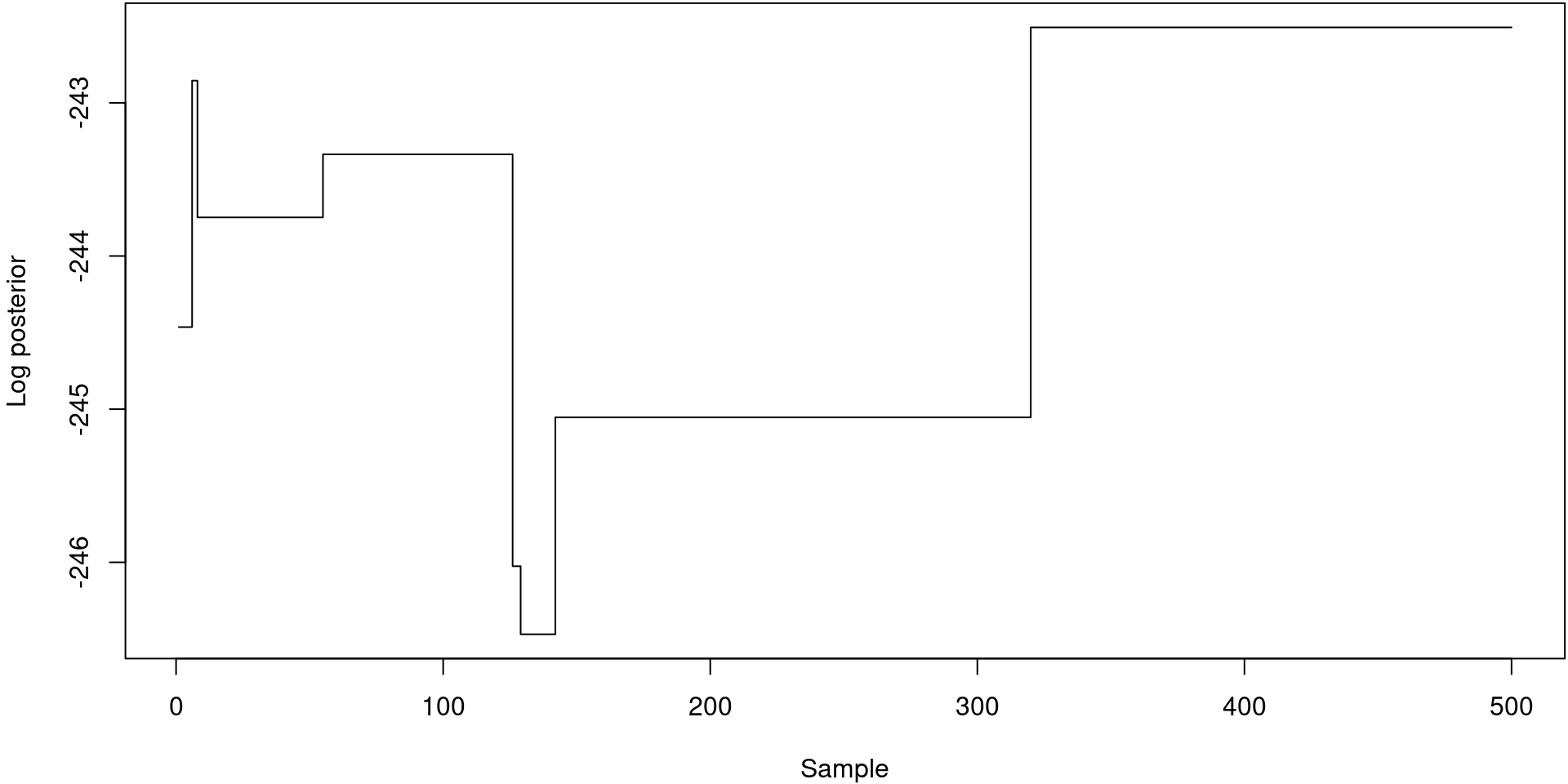
Let’s try again
vcv <- matrix(c(0.00057, 0.00052, 0.00052, 0.00057), 2, 2)
mcmc_pars <- mcstate::pmcmc_parameters$new(priors, vcv, transform)
control <- mcstate::pmcmc_control(
n_steps = 500,
n_chains = 4,
n_threads_total = 12,
n_workers = 4,
save_state = TRUE,
save_trajectories = TRUE,
progress = TRUE)
samples <- mcstate::pmcmc(mcmc_pars, filter, control = control)
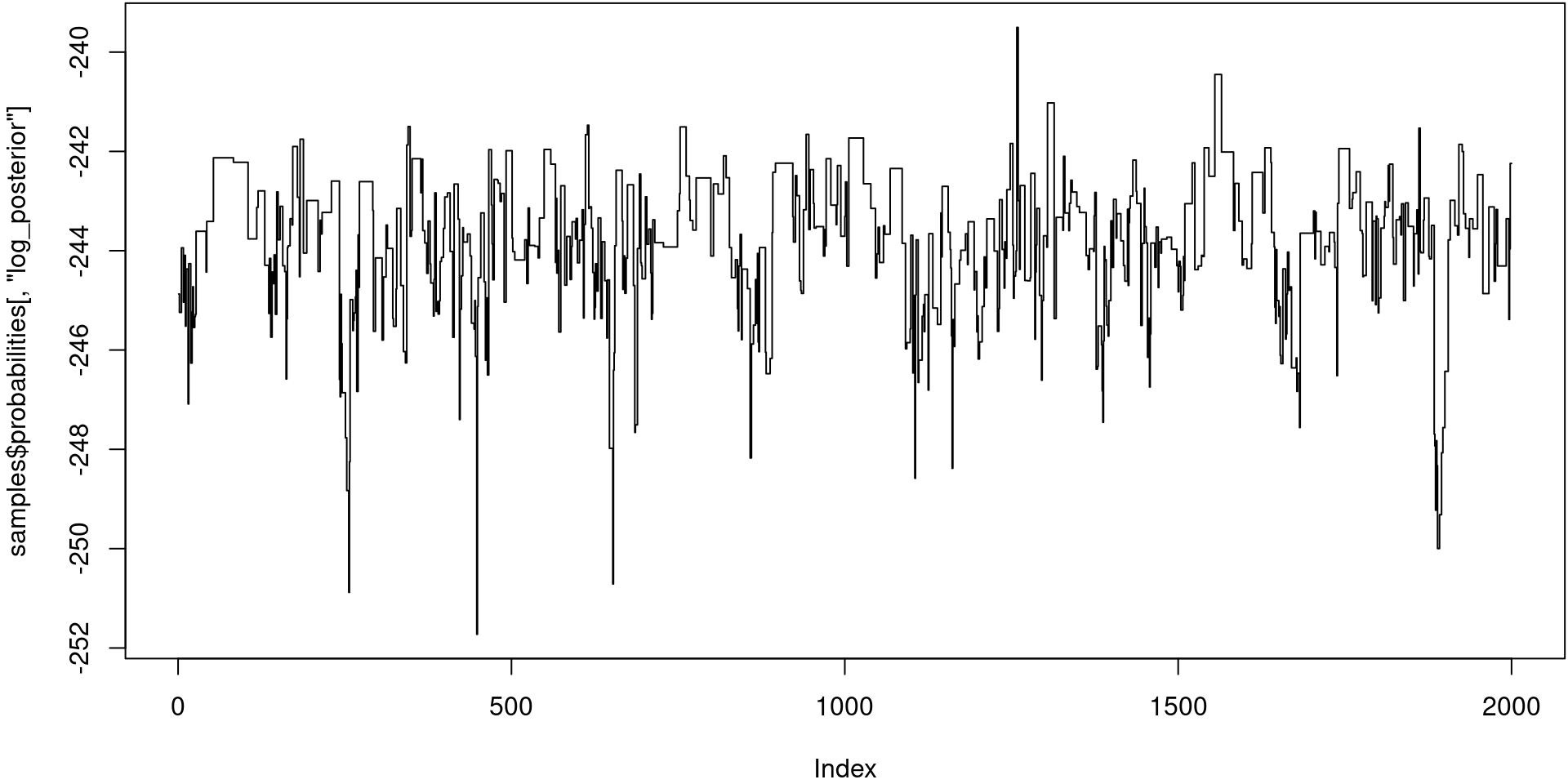
plot(samples$probabilities[, "log_posterior"], type = "s")